基于栈 or 寄存器的 VM 有啥区别?
最近项目中有涉及 Lua,在查阅其 VM 资料时发现:从 5.0 开始,用了十年的基于栈的 VM 切换到了基于寄存器的 VM。
猛然联想到,当年校招背 Android 八股文时,也有一段类似的描述:“与基于栈的 JVM 不同,Dalvik 基于寄存器。”
当时也是一头雾水:有函数调用,就离不开栈,莫非基于寄存器的 VM 还能做到不用栈?
初出茅庐时囫囵吞枣、不求甚解,结果多年后终究还是绕不开这个话题。看来必须得搞清楚。
首先声明一点,这里讨论的是进程虚拟机,而不是 VMWare、VirtualBox 那种系统虚拟机。
寄存器的特点
我们知道,寄存器的特点:
离 CPU 最近,速度比内存还快;
访问寄存器通过名字(如
PC、SP、LR),而不是像内存一样通过地址;
基于栈的 VM
VM 基于栈,是指:
指令集包含 PUSH/POP 等栈操作;
指令操作数存在栈中。
下面我们以加法为例:
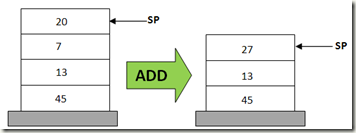
因为指令操作数都保存在栈中,所以我们要先依次 POP,然后执行 ADD,最后 PUSH 结果:
POP
POP
ADD
PUSH由此可以看出基于栈的 VM 的特点:
实现简单(不需要跟不同架构硬件的寄存器打交道);
指令需要分发的次数多(需要额外的 PUSH/POP 操作),对性能有较大影响;
由于实现简单,较早出的 JVM、.NET CLR、Lua 5.0 以前的 VM 等,都是这个方案。
JVM 的栈相关的指令
我们看看 JVM 部分栈相关的指令:
iload:将本地变量压栈;bipush:将byte压栈,作为整数;sipush:将short压栈,作为整数;pop:出栈一个元素;pop2:出栈两个元素;swap:交换栈顶的两个元素;
当然不止这些,从这里可以看到,相当多的指令都是和栈有关的。
有论文指出,超过 40% 的 JVM 指令都是用于本地变量和栈之间的操作。
比如 JVM 实现上面的加法:
iload_1 #加载变量 1
iload_2 #加载变量 2
iadd
istore_3 #存储结果到变量 3基于寄存器的 VM
VM 基于寄存器,是指:
指令集没有 PUSH/POP 等栈操作;
指令操作数存在寄存器。
仍然以加法为例:
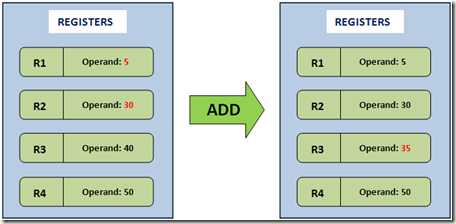
因为指令操作数都保存在不同的寄存器,所以只需要一条指令带上寄存器名字即可:
ADD R1, R2, R3由此可以看出基于寄存器的 VM 的特点:
实现较复杂(需要跟不同架构机器的寄存器打交道);
指令需要分发的次数少,性能高;
指令平均长度大(始终要带上操作数);
结果存在单独的寄存器,可用于缓存临时结果,避免重复计算;
基于性能好,较晚出的 Lua 5.0 VM、Dalvik、Rust VM 等,都是这种方案。