音频处理相关梳理
关于音频处理,最近之前做智能语音助手简单接触过 speex 压缩,最近做直播算是有了更进一步的认识,这里简单做下梳理。
常用处理
调整音量
我们知道,声音是波,而音量对应声波的振幅。
所以直接调整音频数据的数值(通常是乘以一个系数)就能改变音量:
for (int i = 0; i < len/2; i++) {
SInt16 value = (buf[2*i+1] << 8 | (buf[2*i] & 0xFF));
buf[2*i] = value;
buf[2*i+1] = value >> 8;
}防止爆音
但是实际调试中发现会出现爆音,一般的解决方式是限制下值的范围:
#define LIMIT_AUDIO(a) ((a)<(-32768.0f) ? (-32768.0f) : ((a)>(32767.0f) ? (32767.0f) : (a)))为什么要这么做呢?
因为通常音频采样的位宽是 16 bits,对应的二进制范围就是 [-32768, 32767]。
混音
同样是类比物理中波的概念,每路声音对应一个波形,声音叠加(混音)就是波的叠加:
for (int i = 0; i < len/2; i++) {
SInt16 input1Value = (input1[2*i + 1] << 8 | (input1[2*i] & 0xFF));
SInt16 input2Value = (input2[2*i + 1] << 8 | (input2[2*i] & 0xFF));
output[2*i] = outputValue;
output[2*i+1] = (outputValue >> 8);
}大小端转换
在做内录混音的时候,发现最终总是听不到内录的声音。
请教了下组里的老司机,说可能是大小端问题。
那什么是大小端呢?
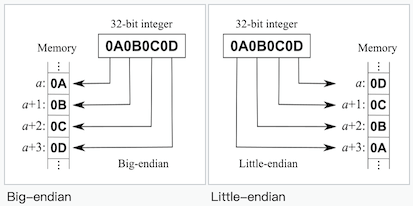
大端,常用于网络传输(重要的头部数据放最前面);
小端,常用于 CPU 处理内存数据。
可以看到,其实就是低位高位顺序的不同,所以先读取后面的即可实现大小端转换:
Byte *byteArray = (Byte*)[data bytes];
NSMutableData *audioData = [NSMutableData new];
for (int i = 0; i < [data length] / 2; i++) {
[audioData appendBytes: &byteArray[i*2+1] length:1];
[audioData appendBytes: &byteArray[i*2] length:1];
}对于 iOS/MacOS,其实 CoreFoundation 的 CFByteOrder.h 已经提供了字节序相关的接口:
//获取当前机器大小端模式:
CFByteOrderGetCurrent();
//将 32 位的整型从大端转为本机的模式(若本机为大端,则原值不变)
uint32_t CFSwapInt32BigToHost(uint32_t arg);
//将 32 位的整型从本机的模式转为大端(若本机为大端,则原值不变)
uint32_t CFSwapInt32HostToBig(uint32_t arg);
//将 32 位的整型从小端转为本机的模式(若本机为小端,则原值不变)
uint32_t CFSwapInt32LittleToHost(uint32_t arg);
//将 32 位的整型从本机的模式转为小端(若本机为小端,则原值不变)
uint32_t CFSwapInt32HostToLittle(uint32_t arg);提取单声道
由于左右声道数据是相间的,所以交叉读写即可:
FILE *fp = fopen(url, "rb+");
FILE *fp1 = fopen("output_l.pcm", "wb+");
FILE *fp2 = fopen("output_r.pcm", "wb+");
unsigned char *sample = (unsigned char *)malloc(4);
while(!feof(fp)) {
fread(sample, 1, 4, fp);
fwrite(sample, 1, 2, fp1); //左声道
fwrite(sample+2, 1, 2, fp2); //右声道
}提高音频播放速度
直接采样即可,即周期性丢掉数据,跟 前面提到过的 YUV 缩放同一个套路:
int cnt = 0;
unsigned char *sample = (unsigned char *)malloc(4);
while (!feof(fp)) {
fread(sample, 1, 4, fp);
if (cnt % 2 != 0) {
fwrite(sample, 1, 2, fp1);
fwrite(sample + 2, 1, 2, fp1);
}
cnt++;
}音频压缩编码
MDCT
在前面介绍图像和视频压缩的时候,有提到傅里叶变换,准确地说是离散余弦变换(DCT)。
其实 DCT 在音频压缩领域也有大量应用,MP3、AAC、WMA 等压缩编码都基于 Modified discrete cosine transform。
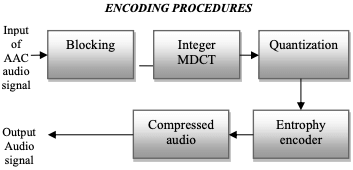
上图就是 AAC 的编码流程,核心流程仍然是:分块、DCT、量化、熵编码。
LPC
除了 MDCT,还有一类压缩算法基于线性预测(Linear predictive coding),例如语音识别领域常用的 Speex。
其基本思想是:一个语音的抽样能够用过去若干个语音抽样的线性组合来逼近。
对这块没有深入了解,有兴趣的可以参考哥伦比亚大学的课件。
Opus
Opus 则融合了基于 MDCT 的 CELT 算法和基于 LPC 的 SILK 算法,不仅开源,并且在性能上具有明显优势:
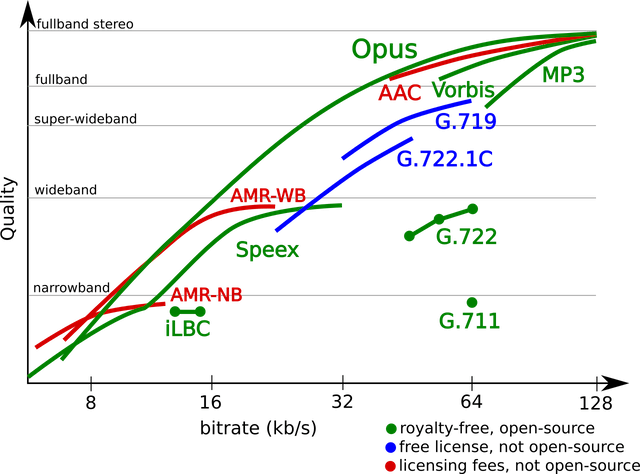
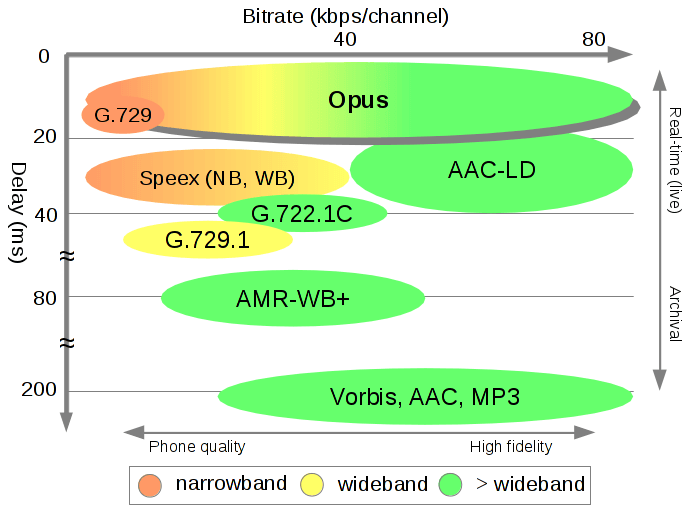
特别适合直播等实时领域。