继续深挖 Android/iOS 的图形内存共享
前文在聊到跨 CPU/GPU 内存共享时,提到 Android 的外部纹理和 iOS 的 IOSurface,但并未深入展开。
那么,为什么它们能实现内存共享呢?
先说结论:但凡涉及零拷贝内存共享,基本都离不开硬件的 DMA 能力。
下面我们抽丝剥茧地聊一聊。
CPU-GPU 内存架构
讨论跨 CPU/GPU 内存共享之前,我们先简单过一下 CPU-GPU 内存架构,主要分为两种:
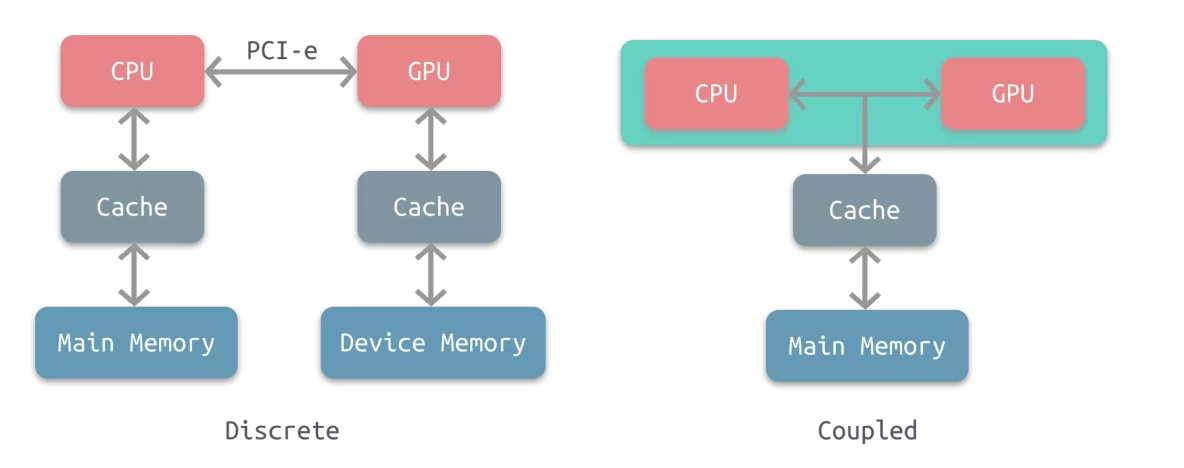
耦合式:
CPU 和 GPU 共享内存,由 MMU 进行内存管理;
主要用于 AMD 的 APU;
分离式:
CPU 和 GPU 各自拥有独立的内存,绝大多数设备都是这种架构;
通过 IOMMU 做内存映射,GPU 与 CPU 得以共享虚拟地址空间;并通过 DMA 绕过 CPU 实现高性能 IO;
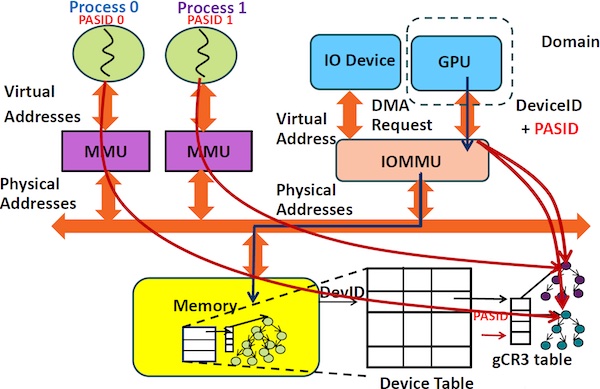
在 PC 上,MMU 和 IOMMU 通过 PCI-e 总线相连(传统 IO 设备则使用南桥芯片),传输速率高;
如分离式架构的典型代表 HSA(Heterogeneous System Architecture):
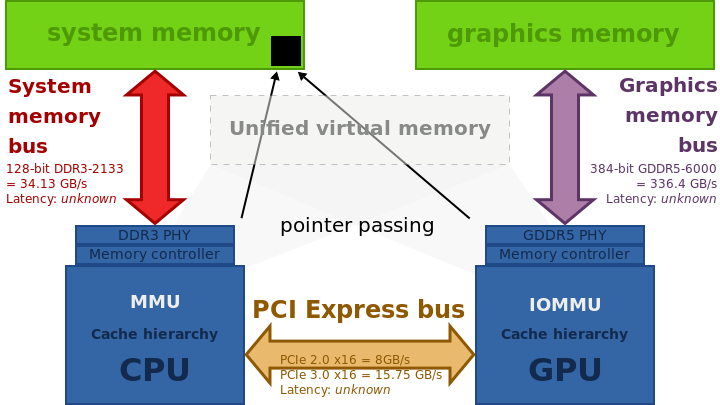
不过,CPU 和 GPU 共享地址空间存在缓存一致性问题;为此,AMD 推出了 hUMA,更多细节可参考 Heterogeneous Architecture。
通用的零拷贝内存共享方案:基于 DMA 的 mmap
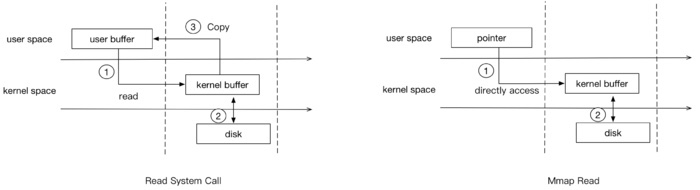
传统的 read 系统调用:
用户进程无法直接访问 kernel space,数据在 kernel space 和 user space 间存在多次拷贝;
需要 CPU 参与,忙于 IO 操作;
DMA 将 CPU 从 IO 操作中解放:
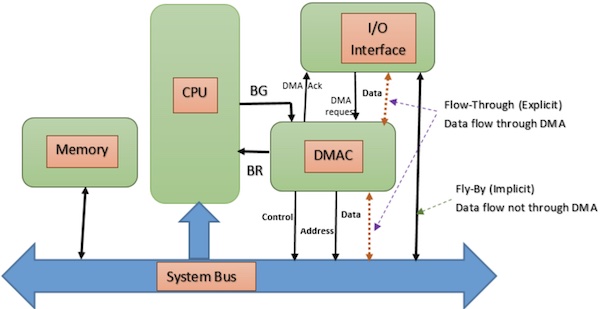
通过独立的芯片,直接访问网卡、声卡、显卡、磁盘等;
DMA 控制器返回内存指针,用于读写;
CPU 不再直接参与 IO 操作,只需等待 DMA 控制器处理完数据后发出中断;
基于 DMA 的 mmap:
将 kernel space 映射到 user space,无需 kernel space 和 user space 间的拷贝;
通过 DMA 执行 kernel space 和磁盘间的拷贝,无需劳烦 CPU;
用户进程通过指针访问映射后的 page cache:
如果已经映射到物理内存,直接内存拷贝;否则发生缺页中断,由于操作系统处理;
脏数据也由操作系统异步写回磁盘。
mmap 主要的 API:
mmap():执行内存映射,返回指针;prot参数为内存保护标识:是否能读写、执行;flags参数为映射类型:是否共享、可被置换;
munmap():解除内存映射;解除后如果再操作原指针会发生段错误;
解除后还会触发脏数据写回磁盘;
msync():强制写回磁盘;mremap():再次映射。
mmap 也不是万能的:
不适合数据频繁更新的场景:会触发大量的脏页回写及由此引发的随机 IO;
不适合特别小的文件:内存映射以页为单位,太小的文件浪费内存空间;
不应该用于可移动磁盘或网络磁盘。
Android 的 mmap 支持
SharedMemory
Android 最上层提供了 MemoryFile,内部实际上调用的是 SharedMemory:
public MemoryFile(String name, int length) throws IOException {
//...
mSharedMemory = SharedMemory.create(name, length);
mMapping = mSharedMemory.mapReadWrite();
//...
}它们二者有啥区别呢:
Applications should generally prefer to use SharedMemory which offers more flexible access & control over the shared memory region than MemoryFile does.
SharedMemory 的 map() 方法调用的 Os.java:
public @NonNull ByteBuffer map(int prot, int offset, int length) throws ErrnoException {
//...
long address = Os.mmap(0, length, prot, OsConstants.MAP_SHARED, mFileDescriptor, offset);
//...
}后续的调用链为:Os.java -> Libcore.java -> Linux.java -> libcore_io_Linux.cpp,
最终调用的是 mmap64 系统调用:
#include <sys/syscall.h>
//...
static jlong Linux_mmap(JNIEnv* env, jobject, jlong address, jlong byteCount, jint prot, jint flags, jobject javaFd, jlong offset) {
//...
void* ptr = mmap64(suggestedPtr, byteCount, prot, flags, fd, offset);
//...
}SYSCALLS.TXT 定义了所有的系统调用,里面也有 mmap 相关的:
# (mmap only gets two lines because we only used the 64-bit variant on 32-bit systems.)
void* __mmap2:mmap2(void*, size_t, int, int, int, long) lp32
void* mmap|mmap64(void*, size_t, int, int, int, off_t) lp64
int munmap(void*, size_t) all
void* __mremap:mremap(void*, size_t, size_t, int, void*) all
int msync(const void*, size_t, int) all函数后面的 lp32、lp64、all 表示 CPU 架构。
DMA-BUF
如果打破砂锅问到底,驱动层其实是基于 ION,Android 12 切换到 DMA-BUF,后者源自 Linux。
驱动层超出了本文的讨论范围,具体可参考:
iOS 的 mmap 支持
由于 iOS/MacOS 内核基于 FreeBSD,跟 Linux 一样属于类 POSIX,所以也提供了 mmap 相关支持:mmap()、munmap()、msync();
但是有两点需要注意:
iOS/MacOS 不支持
mremap(),可参考:Is there really no mremap in Darwin?NSData的dataWithContentsOfFile:options:也支持 mmap 的方式,需要将NSDataReadingOptions指定为NSDataReadingMappedIfSafe或NSDataReadingMappedAlways;
这个
Safe主要针对 MacOS,如果是网络磁盘、可移动磁盘,就可能不安全(映射过程中文件突然不可访问);
Android 的 Ashmem 子系统
我们知道,mmap() 倒数第二个参数 fd 是个文件描述符,而 Ashmem 就是 Android 提供的虚拟内存分配器:
ashmem_create_region()返回一个描述符fd;文件描述符除了传给
mmap(),还通过 Binder 传递给其他进程,实现跨进程共享。
Ashmem 驱动层的实现位于 drivers/staging/android/ashmem.c,具体逻辑就不展开分析,说几个关键点:
Ashmem 生命周期;
通过
ashmem_create_region()创建的共享内存默认是pined状态:除非主动关闭fd,否则保持到进程死亡;ashmem_unpin()会将共享内存解除锁定,当系统内存不足时,会将其释放;再次使用同一段内存前,应先调用
ashmem_pin(),若返回ASHMEM_WAS_PURGED,说明已被回收,再次访问会触发缺页中断;
再探 SharedMemory
上面分析 SharedMemory 可能容易漏掉最后有个 native 方法 nCreate() 返回文件描述符:
private static native FileDescriptor nCreate(String name, int size) throws ErrnoException;native 层实现 android_os_SharedMemory.cpp中,调用的正是 ashmem 接口:
jobject SharedMemory_nCreate(JNIEnv* env, jobject, jstring jname, jint size) {
//...
int fd = ashmem_create_region(name, size);
//...
}MemoryHeapBase
上面提到,文件描述符通过 Binder 跨进程传输,这里涉及的关键角色就是 MemoryHeapBase,其内部也是调用 mmap 和 Ashmem 接口。
具体逻辑不展开,总之一句话:
Android 内存共享的关键就是 mmap + Ashmem。
Android 的图形内存共享
之前在探讨 FileChannel 时,也简单提到过 DMA 和 mmap,算是在普通 IO 场景的应用;接下来主要探讨图形内存共享场景。
GraphicBuffer 是 Android 的核心图形数据结构
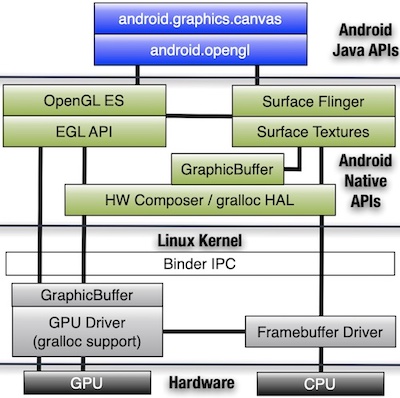
对 Android 图形系统,无论普通 View 的 Canvas 绘制,还是基于 Surface 的 OpenGL 绘制,底层最基本的图形数据结构都是 GraphicBuffer;
GraphicBuffer 通过 BufferQueue 以队列形式存储,外部以生产者-消费者模型操作这个队列。比如:
图像采集时,外部纹理可以直接写入
BufferQueue,它是生产者;MediaCodec 硬编码,设置了输入
Surface时,它是消费者;
GraphicBuffer 基于 Ashmem 和 mmap 实现
GraphicBuffer 通过 GraphicBufferAllocator 和 GraphicBufferMapper 调用 Gralloc,最终正是调用了 Ashmem 和 mmap:
static int gralloc_alloc_buffer(alloc_device_t* dev, size_t size, int usage, buffer_handle_t* pHandle) {
//...
fd = ashmem_create_region("gralloc-buffer", size);
//...
}
static int init_pmem_area_locked(private_module_t* m) {
//...
void* base = mmap(0, size, PROT_READ|PROT_WRITE, MAP_SHARED, master_fd, 0);
//...
}Surface 实际操作的是 GraphicBuffer
那么,GraphicBuffer 是如何跟上层的 Surface 产生关联的呢?
且看 GraphicBuffer.h 中的定义:
class GraphicBuffer
: public ANativeObjectBase<ANativeWindowBuffer, GraphicBuffer, RefBase>,
public Flattenable<GraphicBuffer>GraphicBuffer 继承自 ANativeObjectBase,它是一个支持引用计数的模板类:
/*
* This helper class turns a ANativeXXX object type into a C++
* reference-counted object; with proper type conversions.
*/
template <typename NATIVE_TYPE, typename TYPE, typename REF,
typename NATIVE_BASE = android_native_base_t>
class ANativeObjectBase : public NATIVE_TYPE, public REF且模板参数传入的是 ANativeWindowBuffer。
而 Surface 内部操作的正是 ANativeWindowBuffer:
virtual int dequeueBuffer(ANativeWindowBuffer** buffer, int* fenceFd);
virtual int cancelBuffer(ANativeWindowBuffer* buffer, int fenceFd);
virtual int queueBuffer(ANativeWindowBuffer* buffer, int fenceFd);
virtual int lockBuffer_DEPRECATED(ANativeWindowBuffer* buffer);正因为
Surface封的是GraphicBuffer的句柄,且实现了Parcelable接口,所以能通过 AIDL 实现跨进程渲染。
HardwareBuffer 是对 GraphicBuffer 的封装
上面讨论的 GraphicBuffer 和 ANativeWindowBuffer 都是系统底层的数据结构,对应用层不开放;
Android 8.0 开始,应用层开放了 HardwareBuffer(也实现了 Parcelable 接口),NDK 层是 AHarwareBuffer。
从 AHardwareBuffer.cpp 可以看出,内部调用的正是 GraphicBuffer:
int AHardwareBuffer_allocate(const AHardwareBuffer_Desc* desc, AHardwareBuffer** outBuffer) {
//...
uint64_t usage = AHardwareBuffer_convertToGrallocUsageBits(desc->usage);
sp<GraphicBuffer> gbuffer(new GraphicBuffer(desc->width, desc->height, format, desc->layers, usage, std::string("AHardwareBuffer pid [") + std::to_string(getpid()) + "]"));
//...
GraphicBuffer::dumpAllocationsToSystemLog();
//...
*outBuffer = AHardwareBuffer_from_GraphicBuffer(gbuffer.get());
//...
}更多 Android 底层显示系统的内容,可移步我之前写的另一篇文章:深入理解 Android:Surface 系统。
iOS 的图形内存共享
IOSurface 是 iOS 的核心图形数据结构
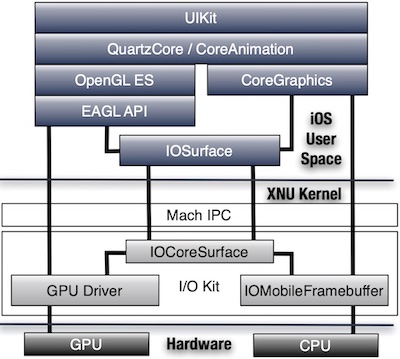
从前文我们已经知道,iOS 中无论是图像采集、渲染还是 VideoToolBox 硬编码,内存共享都离不开 IOSurface;
其实 CoreGraphics 底层也是 IOSurface,只不过它是通过 CPU 操作;
跨进程访问 IOSurface 是通过 Mach IPC。
深入 IOSurface
前面我们说过,只要涉及到零拷贝内存共享,基本都离不开 DMA,IOSurface 也不例外。
IOSurfaceAccelerator 通过 AppleM2Scaler 调用驱动层内存映射能力:
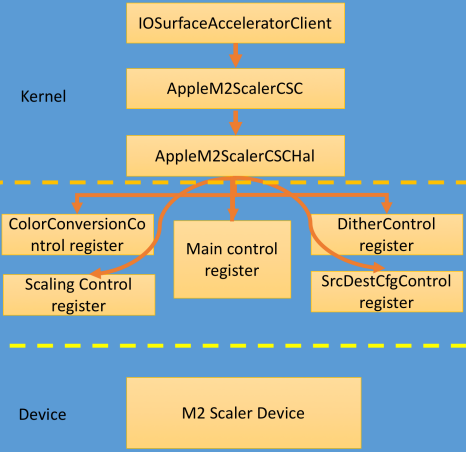
而 AppleM2Scaler 最终通过 IODMACommand 调用 DMA 相关能力:
AppleM2ScalerCSCDriver::setPreparedMemoryDescriptor(
AppleM2ScalerCSCDriver *this,
QWORD a2, void *а3, IOMemoryDescriptor *descriptor) {
//...
v8 = IODMACommand::withSpecification(
(__int64)OutputLittle32,
0x20LL, 0LL, 0LL, 0LL, 1LL,
(_int64)v6->m_IOMapper,
0LL);
//...
v12 = IODMACommand::setMemoryDescriptor(v8, descriptor, 1LL);
}
AppleM2ScalerCSCDriver::mapDescriptorMemory(
AppleM2ScalerCSCDriver *this,
_int64 a2, void *a3,
IOMemoryDescriptor *a4, unsigned _int64 a5, unsigned int64 a6) {
//...
if (v8->m_IOMapper) {
v13 = IODMACommand::genIOVMSegments(
(IODMACommand *)v12,
(unsigned _int64 *)&v32,
&v33,
(unsigned int *)&v31);
v20 = IOSurface::getPlane0ffset(v10->pBuffer, 0);
v10->PA0 = v20 + v33;
}
//...
}更多细节可以通过腾讯科恩实验室的这次分享去了解。
图形引擎的跨 CPU/GPU 内存共享方案
OpenGL 的 PBO
前文已详细介绍了 OpenGL 的 PBO 机制,这里不再赘述,其底层同样是利用了 DMA + 内存映射。
Vulkan 的内存映射
首先 Vulkan 也提供了 vkCmdCopyBufferToImage() 和 vkCmdCopyImageToBuffer(),类似 OpenGL 的glTexImage2D() 和 glReadPixles();
然后,类似 PBO,Vulkan 也提供了内存映射的方案 vkMapMemory() / vkUnmapMemory()。
不过官方的这套方案有些缺陷:
同一块
VkDeviceMemory只能映射一次;内部没有引用计数机制。
因此,AMD 的 GPUOpen 推出了 Vulkan Memory Allocator,解决了上面两个问题。
而 vkguide.dev 的 Memory transfer 部分也是采用的 VMA:
void* mappedData;
vmaMapMemory(allocator, constantBufferAllocation, &mappedData);
memcpy(mappedData, &constantBufferData, sizeof(constantBufferData));
vmaUnmapMemory(allocator, constantBufferAllocation);除了临时映射,通过 VMA 还可创建一块永久处于映射状态的内存,只需指定 VmaAllocationCreateInfo 的 flags 为 VMA_ALLOCATION_CREATE_MAPPED_BIT。
VkBufferCreateInfo bufCreateInfo = { VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO };
bufCreateInfo.size = 65536;
bufCreateInfo.usage = VK_BUFFER_USAGE_TRANSFER_SRC_BIT; //上传纹理数据
//bufCreateInfo.usage = VK_BUFFER_USAGE_TRANSFER_DST_BIT; //下载纹理数据
VmaAllocationCreateInfo allocCreateInfo = {};
allocCreateInfo.usage = VMA_MEMORY_USAGE_AUTO;
allocCreateInfo.flags = VMA_ALLOCATION_CREATE_MAPPED_BIT;
allocCreateInfo.flags |= VMA_ALLOCATION_CREATE_HOST_ACCESS_SEQUENTIAL_WRITE_BIT; //上传纹理数据
//allocCreateInfo.flags |= VMA_ALLOCATION_CREATE_HOST_ACCESS_RANDOM_BIT; //下载纹理数据
VkBuffer buf;
VmaAllocation alloc;
VmaAllocationInfo allocInfo;
vmaCreateBuffer(allocator, &bufCreateInfo, &allocCreateInfo, &buf, &alloc, &allocInfo);
memcpy(allocInfo.pMappedData, myData, myDataSize);映射好 buffer 以后,进而创建 VkImage:
VkImageCreateInfo imgCreateInfo = { VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO };
imgCreateInfo.imageType = VK_IMAGE_TYPE_2D;
imgCreateInfo.extent.width = 3840;
imgCreateInfo.extent.height = 2160;
imgCreateInfo.extent.depth = 1;
imgCreateInfo.mipLevels = 1;
imgCreateInfo.arrayLayers = 1;
imgCreateInfo.format = VK_FORMAT_R8G8B8A8_UNORM;
imgCreateInfo.tiling = VK_IMAGE_TILING_OPTIMAL;
imgCreateInfo.initialLayout = VK_IMAGE_LAYOUT_UNDEFINED;
imgCreateInfo.usage = VK_IMAGE_USAGE_SAMPLED_BIT | VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT;
imgCreateInfo.samples = VK_SAMPLE_COUNT_1_BIT;
VkImage img;
vmaCreateImage(allocator, &imgCreateInfo, &allocCreateInfo, &img, &alloc, nullptr);这样,在 CPU 端通过指针读写 buffer,就能实现读写纹理。是不是跟 PBO 或者 iOS 的 CVPixelBuffer 机制很像?
更多 VMA 的使用方式可参考 Vulkan Memory Allocator: usage patterns。
内存共享的第三方典型应用
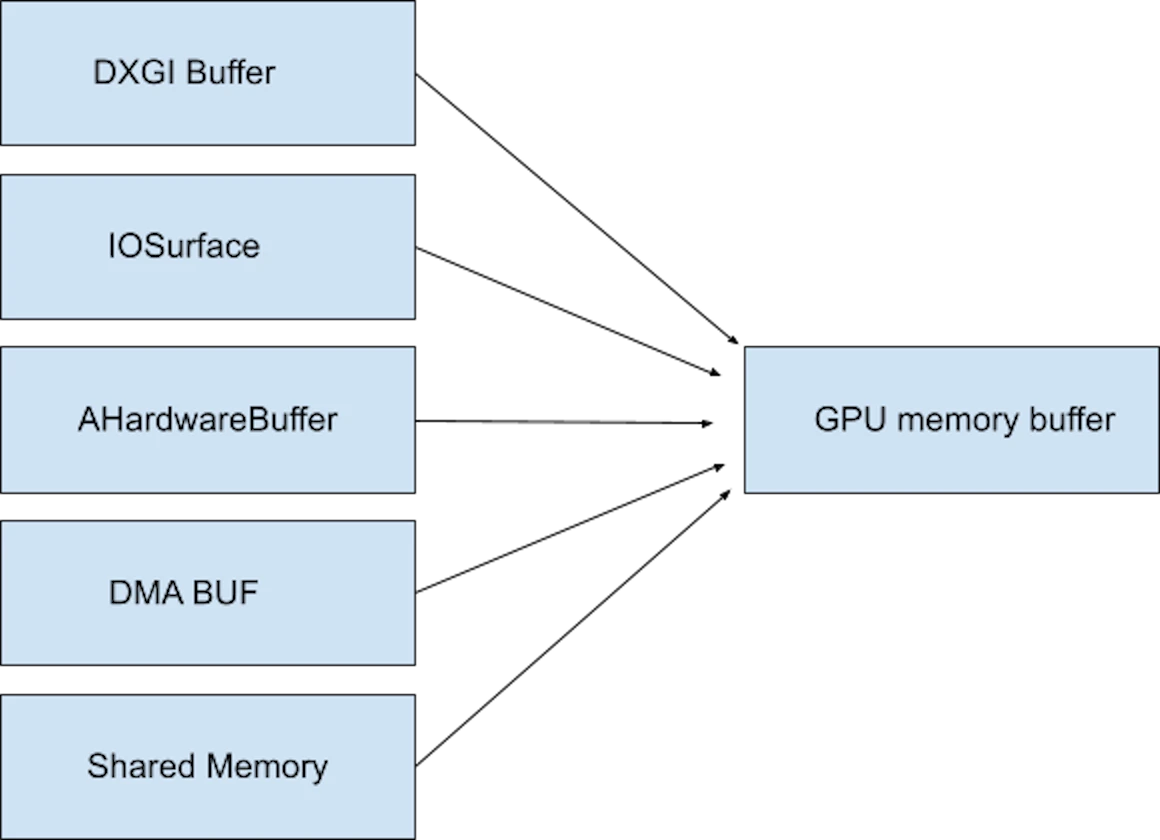
Chrome
Chrome 的 GpuMemoryBuffer 就是基于 Android 的 AHardwareBuffer 和 Apple 的 IOSurface:
更多内容可参考 Chrome Developers: Deep dive VideoNG。