现代 C++ 跨平台开发-内存篇:内存一致性、未定义行为、可观测性
本文是整个【现代 C++ 跨平台开发-内存篇】系列的第 6 篇,主要涉及:内存一致性、未定义行为、可观测性等。
现代 C++ 跨平台开发-内存篇:内存一致性、未定义行为、可观测性
内存一致性
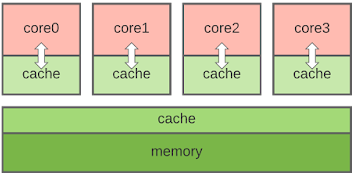
多核 CPU 缓存一致性架构模型
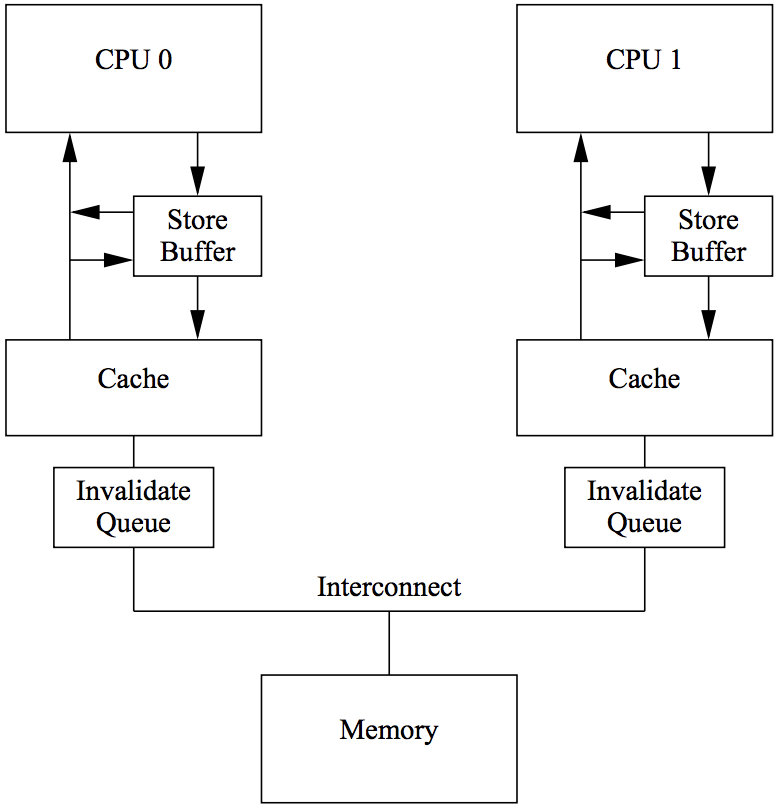
Store Buffer
CPU 和 Cache 之间的临时队列,暂存写操作(store)指令;
允许 CPU 快速“完成”写操作,而不必等待数据真正写入 Cache 或主存;
Invalidate Queue
接收其他 CPU 的“无效化请求”(invalidate request);
通知本 CPU 某个缓存行已过期,需要失效;
Interconnect
- 多个 CPU 核心之间的通信通道,负责传递缓存一致性消息。
C++ 内存序
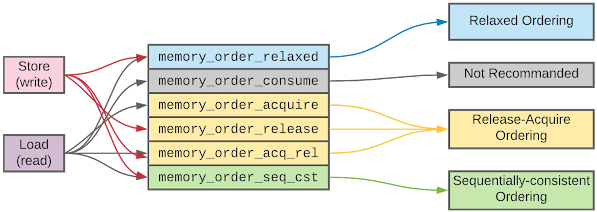
sequential consistent ordering(顺序一致模型)
保证严格的全局 CPU 缓存一致性(任何改动立即同步到所有 CPU 核心),开销大;
对应代码层面的
memory_order_seq_cst;
acquire-release ordering
保证基本的 CPU 各核心之间局部缓存一致性;
对应代码层面的:
memory_order_acquire,常用于读操作(load);memory_order_acq_rel,用于既读又写;memory_order_release,常用于写操作(store);
影响指令重排:任何指令都不会重排到 acquire 之前、 release 之后;
relaxed ordering(宽松模型)
写只操作所在核心的本地缓存,不保证同步;
对应代码层面的
memory_order_relaxed;适合不需要严格多线程同步的场景:数据统计等;
其他模型
对应代码层面的
memory_order_consume;没有 acquire 严格,只要求有依赖关系的指令不能重排到前面;
本意是为了相比 acquire 提升性能,但真要实现很复杂,某些编译器甚至直接当 acquire 处理,可能后面会废弃。
volatile
不同于 Java,C/C++ 的
volatile并没有内存可见性语义。
早期 C/C++ 没有统一的跨平台内存模型,在此背景下诞生;
不严格保证内存可见性和原子性:仅阻止编译期访问相关优化(寄存器缓存、指令重排),不限制运行期 CPU/内存重排,不会插入内存屏障指令;
不是为多线程场景设计的,而是为内存映射等场景设计的。
// 禁止读优化:
volatile int flag = 0;
while (flag == 0) { } // 不能假设 flag 不变而优化成死循环,必须每次从内存读取
// 禁止写优化:
volatile int reg = 0;
reg = 1; // 必须实际写入内存(可能映射到硬件寄存器)
reg = 2; // 不能合并或删除第一次写
// 禁止编译期指令重排:
volatile int a, b;
a = 1;
b = 2; // 不能交换这两条写入顺序std::atomic
性能最高:lock-free(直接使用 CPU 同步指令),不会卷入内核,没有上下文切换;
只适合简单非耗时任务;
直接当普通变量读写时,默认使用
memory_order_seq_cst;所以尽量使用 load/store。适用范围:
本来只能用于平凡类型;
C++20 提供了
atomic<shared_ptr>``、atomic<weak_ptr>,底层利用指针最低位(LSB)存储锁定标识。没有
unique_ptr版本,因为它强调独占所有权,不存在资源竞争;且移动语义很难跟原子操作兼容。
class spinlock {
private:
std::atomic<bool> flag{false};
public:
void lock() {
while (flag.exchange(true, std::memory_order_acquire));
}
void unlock() {
flag.store(false, std::memory_order_release);
}
}False-Sharing
CPU 不会读取单个字节,而是读取一个 Cache-Line(通常 64 字节);其中可能包含多个变量。
多线程访问同一缓存行的多个变量,会产生缓存抖动,导致 False-Sharing。
#include <new>
#if defined(__cpp_lib_hardware_interference_size)
static constexpr size_t CACHE_LINE_SIZE = std::hardware_destructive_interference_size;
#else
static constexpr size_t CACHE_LINE_SIZE = 64;
#endif
struct alignas(CACHE_LINE_SIZE) T {
alignas(CACHE_LINE_SIZE) std::atomic x{false};
alignas(CACHE_LINE_SIZE) std::atomic y{false};
};注意:
使用
hardware_constructive_interference_size不能避免 False-Sharing;只有
struct和class中的atomic成员需要处理,函数中的局部变量不需要处理;
thread_local
数据存储在 TLS 区(一种专属线程的静态存储区):
已初始化的写入
.tdata段;未初始化的写入
.tbss段;生命周期与线程完全一致;
通过专用寄存器(如
FS,GS)和偏移访问,极高效;数据大小有限制,太大会导致线程创建失败;
mimalloc 等第三方库利用
thread_local减少跨线程内存资源的数据竞争。
std::string write(const Json::Value& value) {
/*Json::FastWriter writer;
return writer.write(value);*/
// 复用 buffer,并通过 thread_local 避免资源竞争
static thread_local Json::StreamWriterBuilder builder;
return Json::writeString(builder, value);
}未定义行为(Undefined Behavior)
性能:编译器假设 UB 不会发生,从而进行激进优化;(程序不应该依赖 UB)
硬件抽象:不假设运行在何种硬件,某些操作在特定架构才是 UB;
绝大多数 UB 都是内存相关
读取未初始化的内存:
结构体成员未初始化;
malloc()后读取既未置零也未写入的内存单元;
解引用空指针;
通过毫无关联的不同类型指针访问同一内存;
越界类:
有符号整数溢出;
C 字符串操作未以
\0结尾;memcpy()越界等;
use-after-free:
free()/delete()后继续使用;atd::move()后继续使用;
double-free(重复释放);
union写 a 读 b;函数返回局部引用/指针;
修改
const对象或字符串字面量;C 风格可变参数列表,
va_start和va_end不匹配;多线程数据竞争(内存可见性保证);
constexpr 与 UB
constexpr不允许出现 UB,可用于检测部分 UB。
constexpr int* p = nullptr;
constexpr int x = *p; //编译错误!空指针解引用 UB
constexpr int a = INT_MAX;
constexpr int b = a + 1; //编译错误!有符号整数溢出 UB
constexpr int arr[3] = {1, 2, 3};
constexpr int x = arr[5]; //编译错误!数组越界
编译器利用 UB “优化”
int funA(int *p) {
*p = 42; // 这里直接解引用赋值,编译器假定 p 不会是空指针(否则 UB)
if (p == NULL) return -1; // 编译器可能直接删除此分支!
return 0;
}
int funB(float *f, int *i) {
*f = 1.0f;
*i = 1;
return *f; //编译器假定 f 和 i 不会指向同一内存(否则 UB),优化为:直接返回编译期常量;
}
bool funC(int x) {
return x + 1 < x; //只有溢出的情况下(UB)才会为真,优化为:直接返回 false
}更多未定义行为可参考:
可观测性与 as-if rule
可观测性
C++ 标准规定,必须保证可观测行为与抽象机的某种执行结果一致。
可观测行为:I/O、
volatile、系统调用;内部行为:内存布局、指针地址、临时对象数量、寄存器使用等;
异常也不属于“可观测行为”;
一旦有未定义行为,可观测性保证丧失;
as-if rule
只要最终的可观测行为正确,编译器可以做任何变换。
Copy-On-Write
QString 等第三方容器使用 Copy-on-Write(COW)来优化拷贝性能(仅在首次写入时深拷贝,其余情况共享数据)。
而 C++11 起,std::string 禁止 COW 实现,主要是为了保证:
拷贝(构造/赋值)之后,原字符串的指针(如
data())、引用和迭代器在未修改原对象的前提下始终保持有效。
这一要求是 C++ 抽象机语义的一部分,确保程序行为可预测,避免隐式未定义行为。
现实案例
int a[1000];
for (int i = 0; i < 1000; ++i) a[i] = i;
// 编译器可能:
// - 向量化(并行计算)
// - 消除数组(如果后续没用到)
// - 重排循环(如果无副作用)
for (int j = 0; j < 1000; ++j) {
a[j] = j;
std::cout << a[j] << "\n"; // 出现 I/O,必须保证可观测性(顺序输出)
}