现代 C++ 跨平台开发-内存篇:字节序、内存对齐、内存布局、虚函数表与多态
本文是整个【现代 C++ 跨平台开发-内存篇】系列的第 3 篇,主要涉及:字节序、内存对齐、内存布局、虚函数表与多态等内容。
现代 C++ 跨平台开发-内存篇:字节序、内存对齐、内存布局、虚函数表与多态
ABI
C 有稳定的 ABI,C++ 没有(GCC/Clang 都遵循 Itanium C++ ABI,而 MSVC 有自己的 API)。
跨平台场景通常通过 extern “C” 导出 C 接口,以最大限度保证 ABI 稳定性。
ABI 定义了二进制层面的规范:
数据布局:数据类型大小、结构体对齐方式、类成员布局等。
函数调用约定:参数传递方式、栈的使用、返回值处理等。
名称修饰规则:函数符号命名方式(C++ 支持函数重载,编译生成的函数名带有参数类型);
异常处理机制:异常如何传递和处理(C++ 涉及对象自动析构)。
系统调用方式:应用如何与操作系统交互。
二进制兼容的本质:在平台 A 上生成的一段原始内存(如文件、网络包),能否在平台 B 上被原样解释为相同的逻辑数据。
序列化、内存拷贝是二进制兼容性最核心、最直接的应用场景。
结构体内存布局
内存布局,不仅影响存储空间,而且影响访问效率。
自然对齐规则
对齐值 = 默认取最大成员的对齐值;
偏移量 = 成员对齐值的整数倍;
总大小 = 对齐值的整数倍(不足时填充);
alignof()可用于读取对齐值;
如果内存对齐设置不合理,轻则浪费空间,严重的出现非对齐访问(属于 UB,某些情况直接崩溃)。
设置对齐
alignas
标准方式,强制提升对齐(不能降低)。
struct alignas(16) S {
char a;
int b;
};
// 原本最大成员对齐值为 4 字节,强制提升为 16 字节对齐(不能降低为 2 字节)pack
属于编译器扩展,用于限制最大内存对齐值;
适用场景:严格限制字段填充或保证二进制兼容。
#pragma pack(2)
struct S {
char a; // align=min(1,2)=1
double b; // align=min(8,2)=2,被强制压缩为为 2 字节对齐
};
#pragma pack() // 恢复默认结构体布局优化
字段排序优化
大多数情况,推荐基于自然对齐规则,通过调整字段顺序,优化内存布局:
struct Data0 {
double d; //占 8 位
int i; //占 4 位
char c; //占 1 位,填充 3 位
}; //sizeof(Data0) = 16;填充在结尾,缓存局部性更优!
struct Data1 {
int i; //占 4 位,填充4
double d; //占 8 位
char c; //占 1 位,填充 7 位
}; //sizeof(Data1) = 24;浪费空间!同样存在内部填充!
struct Data2 {
int i; //占 4 位
char c; //占 1 位,填充 3 位
double d; //占 8 位
}; //sizeof(Data1) = 16;填充在中间,破坏缓存局部性!字段聚合方式优化
SIMD(Single Instruction Multiple Data)
并行处理多条相同类型数据,而不是同时处理多个不同字段。
AoS (Array of Structures)
[x0, y0, z0, x1, y1, z1, x2, y2, z2, x3, y3, z3]
- 方便操作单个实体;
SoA (Structure of Arrays)
[x0, x1, x2, x3, y0, y1, y2, y3, z0, z1, z2, z3]
- 适合向量化(SIMD);
AoSoA (Array of Structures of Arrays)
- 混合策略:把数据分成小块,每个块内部是 SoA,块与块之间是 AoS;
constexpr auto LEN = 4;
constexpr auto COUNT = 1024;
// SoA:
struct Chunk {
// 位置:每个分量连续存储 4 个值
float x[LEN], y[LEN], z[LEN];
// 颜色:每个通道连续存储 4 个值
unsigned r[LEN], g[LEN], b[LEN], a[LEN];
};
int main() {
// AoSoA:
Chunk chunks[COUNT];
}C++ 对象内存布局
基本规则
如果不含有虚函数,非静态变量起始地址和类对象地址一样;
静态变量不影响对象内存布局:
若初始化为非默认值,存储在
.data(已初始化数据)段;若未赋值,或赋予默认值,存储在
.bss(未初始化数据)段,节省磁盘空间,加载时自动清零;
成员函数无论是否静态,都存在二进制文件的
.text代码段,不影响对象内存布局:静态成员函数,相比全局函数只是名称 mangle 差异;
普通成员函数,只是多了隐式
this参数;
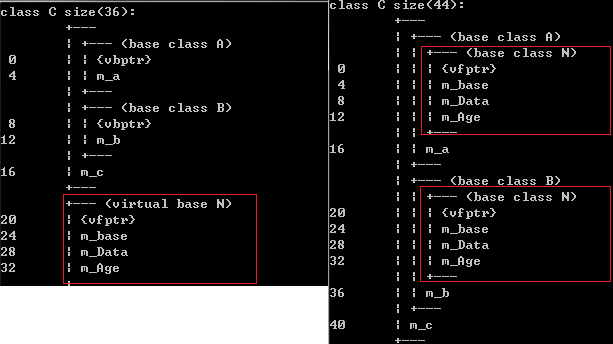
父类的成员变量排在前面,多继承时按继承顺序排,子类成员变量在最后;
菱形继承时,子类会包含两份公共父类的,除非虚继承;
空基类优化
传统 EBO
EBO 即 Empty Base Optimize,空基类优化。
如果一个 C++ 类型没有非静态数据成员、没有虚函数、没有虚基类,则会被编译器优化为:折叠到子类,不额外分配空间。
成员变量只能是静态,但可以有非虚成员函数(包括
operator);非常适合定义接口,常用于
deleter、自定义 hash 函数等;
传统 EBO 的最大问题,就是强依赖继承语义:
私有继承空基类,一个类只能继承一个空基类,且无法继承
final;继承语义(Is-A)不合理,例如 STL 的
allocator默认就是空基类,但 STL 继承它在语义上就很奇怪;
// allocator 属于典型的空基类
template<class T>
struct allocator {
using value_type = T;
T* allocate(std::size_t n);
void deallocate(T* p, std::size_t n);
};
// 为节省空间,STL 一般会私有继承 allocator,而不是将其作为成员
template<typename T, typename Alloc>
class vector_base : private Alloc {
public:
Alloc& get_allocator() { return *this; }
const Alloc& get_allocator() const { return *this; }
protected:
T* begin_;
T* end_;
T* capacity_;
};
template<typename T, typename Alloc = std::allocator<T>>
class vector : private vector_base<T, Alloc> {
//...
};C++20 no_unique_address
C++ 20 引入的 [[no_unique_address]] 解决了传统 EBO 的问题:
不依赖继承,直接在属性前增加关键字即可;
组合语义(Has-A)更合理。
struct Empty {}; // 空类,大小为 1 字节
// 直接内嵌:存在内存浪费
struct WithoutOpt {
int i; // 4 字节
Empty e; // 1 字节 + 3 字节填充 (为了对齐)
};
// sizeof(WithoutOpt) 通常是 8 字节
// 使用 [[no_unique_address]]
struct WithOpt {
int i;
[[no_unique_address]] Empty e; // 空基类优化,布局折叠
};
// sizeof(WithOpt) 可能缩减为 4 字节(仅等于 int 的大小)虚函数表与多态
基于虚函数表的多态
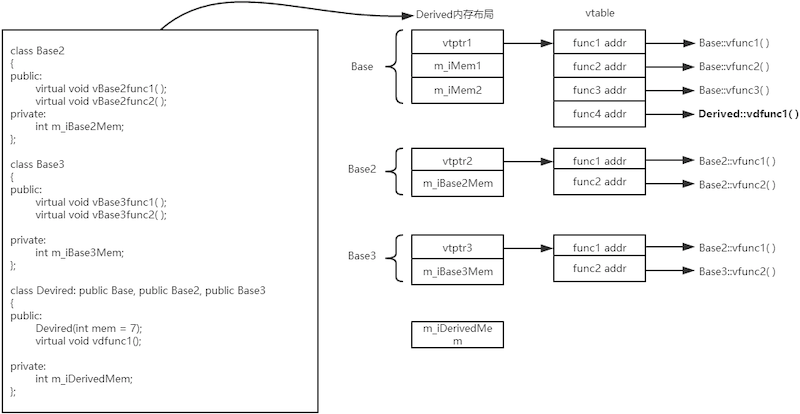
编译时根据类声明创建虚表
vtable,存在只读数据段.rodata(OC 也有类似机制,方法列表编译期写入只读的class_ro_t):Offset (
offset_to_top):多重继承多态场景,通过它可快速从基类起始地址跳转到子类起始地址,以调用其析构;RTTI (
typeinfo):存储类型的名称、大小以及继承关系等信息,以实现dynamic_cast和typeid;除了上述元信息,主要存的就是虚函数地址或 thunk 地址(具体情况见下文);
对象构造时,每个含虚函数的基类子对象的起始位置会写入对应的
vptr,通过它能访问虚表,进而调用虚函数;派生类:
若
override基类虚函数,则替换基类vtable槽位;若声明新虚函数,则追加到主
vtable末尾;
访问控制(
public/protected/private)不影响vtable,仅编译期限制调用合法性;
主基类(Primary Base Class)
在 Itanium C++ ABI(GCC/Clang)中,若有多个基类,编译器会选择一个 “主基类”:
优先选择第一个含有虚函数的非虚基类,否则选第一个基类(简化版规则);
虚继承的基类通常不是主基类;
主基类的子对象与派生类对象共享起始地址。
this 指针 thunk
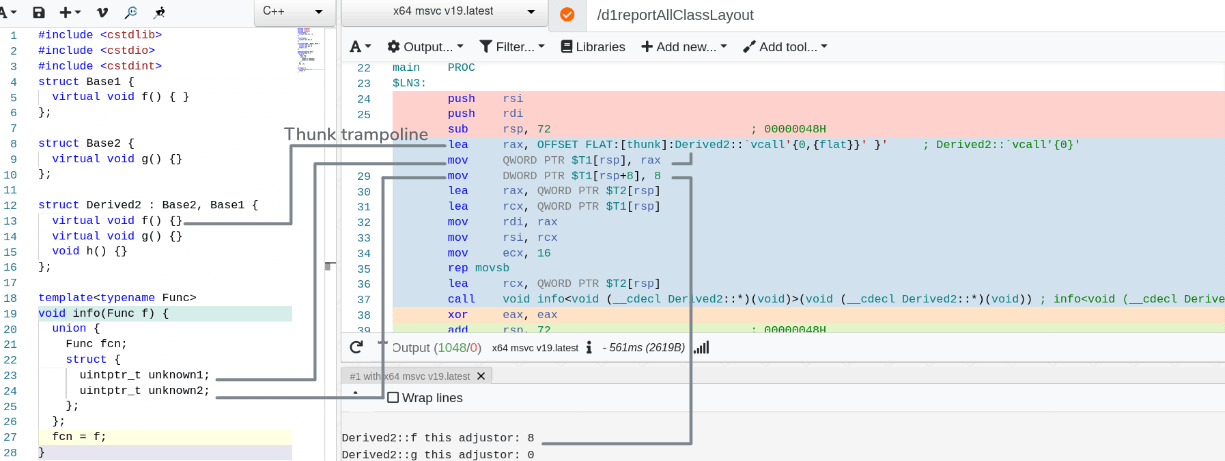
调整
this指针的过程叫 thunk,由编译器生成的一段代码实现:有入口地址,可被
call/jmp,但通常不被视为“普通函数”(无符号名、不直接调用);先对传入的
this指针加上(或减去)一个固定偏移量,再无条件跳转到成员函数的具体实现。
若没有虚函数:
- 所有调用在编译期静态确定,编译器在调用点直接插入指针算术(如
sub rdi, offset)完成this调整,无需 thunk。
- 所有调用在编译期静态确定,编译器在调用点直接插入指针算术(如
若存在虚函数:
若通过主基类指针调用虚函数,仍然不需要 thunk,因为跟子类共享起始地址;
其他情况下:
虚函数表槽位存的是代码段中那一小段 thunk 机器码的地址;
调用流程为:取
vptr-> 查vtable-> 跳转 thunk -> 调整this-> 跳转真实函数。
最初引入虚函数表的合理性
既然虚函数表也是数组,那为啥不直接给每个类新增一个二维函数指针数组成员呢?
自己维护函数指针数组,需考虑 CPU 架构、编译器差异(ABI 兼容)、处理
this指针偏移等各种细节;虚函数表集中存放,更容易命中 CPU cache;分散的函数指针会导致内存访问随机化;
当前看虚函数表存在的问题
内存布局侵入性:
vptr和 padding,破坏缓存局部性(多继承存在多个vptr更糟糕);调用开销:
this指针 thunk,严重影响指令预测和内联优化;OOP 机制僵化:只能继承,无法表达单纯实现
interface,多继承使问题复杂化(菱形继承);
如何避免多态开销
Devirtualization
除了上文提到的主基类场景避免 thunk,编译器还通过 Devirtualization 来尽力避免动态多态开销:
编译器通过静态分析,发现某些情况下能确定最终类型,则会略过查表直接调用:
// 通过分析局部上下文确定类型:
void test() {
Derived d;
Base* b = &d;
b->foo();
}
// 通过 final 关键字确定“仅此一家,别无分号”
class Derived final : public Base { ... };C++ 编译模型以 Translation Unit(一个
.cpp文件 + 所有#include的头文件展开后的结果)为单位。
当虚函数定义、调用点、派生类实现分散在不同 TU,编译器“看不见”全局信息,无法确定是否有其他override,不敢去虚拟化;需要开启 LTO(Link Time Optimization)。
基于 CRTP 的静态多态
CRTP 即 Curiously Recurring Template Pattern:
子类中将基类声明为友元,以便基类调用子类私有实现方法;
不用
dynamic_cast(),而用static_cast();
template
class ZBase {
public:
Bytes ZBase ::process() {
static_cast<T *>(this)->processImp();
}
};
class Zip final : public ZBase {
private:
friend class ZBase;
void processImp() {};
};写法复杂(依赖继承、友元、类型转换)。
基于模板偏特化的静态多态
利用模板偏特化可实现类型萃取,也能用于静态多态:
// 主模板前向声明
template<typename T> struct Processor;
// 类型 trait:只做“类型映射”,不包含任何逻辑
template<typename T>
struct ProcessorTrait {
static_assert(sizeof(T) == 0, "No processor defined for this type!");
};
template<>
struct ProcessorTrait<int> {
using imp = Processor<int>;
};
template<>
struct ProcessorTrait<std::string> {
using imp = Processor<std::string>;
};
// 具体实现:每个类型有自己的 Processor<T>
template<>
struct Processor<int> {
static void print(int x) {
std::cout << "Handle int: " << x << "\n";
}
};
template<>
struct Processor<std::string> {
static void print(const std::string& s) {
std::cout << "Handle string: " << s << "\n";
}
};
// 统一调用入口:通过 trait 获取处理器类型,再调用
template<typename T>
void dispatch_process(const T& value) {
using Imp = typename ProcessorTrait<T>::imp;
Imp::print(value);
}
// ----------
int main() {
dispatch_process(42);
dispatch_process(std::string("world"));
return 0;
}不依赖继承和友元,但写法略复杂,且无编译期类型约束;
基于 C++20 Concept 的静态多态
C++ 20 的 concept 能定义编译期的行为约束(并且编译报错信息友好),可大大简化原有模板偏特化代码。
并且还能组合多个 concept,模拟多继承:
// 定义接口(行为约束)
template<typename T>
concept DrawableT = requires(T t) {
t.draw();
};
template<typename T>
concept ResizableT = requires(T t, float f) {
t.resize(f);
};
// 直接组合 `concept`
template<typename T>
concept DrawableAndResizableT = DrawableT<T> && ResizableT<T>;
// 使用
template<DrawableAndResizableT T>
void process(T& obj) {
obj.draw();
obj.resize(1.5);
}proxy:下一代动态多态框架
微软推出的 proxy 框架解决了传统基于虚函数的动态多态的一系列问题:
template<typename Facade, std::size_t BufferSize = 32>
class proxy {
private:
// 调度表指针(所有 proxy 实例共享同一张表,按具体类型 T 生成)
const vtable_type* vtable_ = nullptr;
// 借鉴了 STL 广泛使用的小对象优化
union {
alignas(std::max_align_t) char buffer_[BufferSize]; // SBO 缓冲区
void* heap_ptr_; // 堆指针(大对象)
};
// 可选的辅助标志:用最低位标记是否在堆上
// 或直接通过模板特化:由 vtable 中的函数隐式知道
};类型擦除:编译期通过模板捕获类型信息并转换为函数指针;
零侵入:
vptr保存在proxy的控制块,不侵入原有类型内存布局;基于行为:不关注类型(可封装任意数据类型),只关注行为(能做什么),并且可以组合多种行为,更契合现代 OOP 强调组合优于继承的理念;
灵活而高效:直接通过函数指针表动态调用,不依赖继承/虚函数;
更现代:充分利用
concept、consteval、if constexpr等新特性做编译期优化;为何另起炉灶:
二进制兼容:原生虚函数表强耦合内存布局,不会轻易做破坏式更新;
目前已进入标准委员会评议阶段,主要纠结的点是大量使用宏(后续静态反射支持以后会改善);
// 利用 `operator()` 空基类,巧妙实现函数指针的零成本“封装”:
// 编译器 EBO 优化后,没有类型信息,只剩静态函数入口地址,比 `std::function` 更高效;
// 仍使用上面 `concept` 定义的行为规范。
struct DrawableImpl {
void operator()(DrawableT auto& self) const { self.draw(); }
};
struct ResizableImpl {
void operator()(ResizableT auto& self, float f) const { self.resize(f); }
};
//定义外观,注册函数指针
PRO_DEF_FACADE(DrawableFacade, DrawableT);
PRO_DEF_FACADE(ResizableFacade, ResizableT);
// 组合两种外观
using DrawableAndResizableFacade = ::pro::combine_t<DrawableFacade, ResizableFacade>;
// 直接定义具体类型,零侵入(无继承、无虚函数)
struct Circle {
void draw() { std::cout << "Drawing a circle\n"; }
void resize(float f) { std::cout << "Resizing circle by " << f << std::endl; }
};
struct Image {
void draw() { std::cout << "Rendering image\n"; }
void resize(float f) { std::cout << "Scaling image to " << f << std::endl; }
};
int main() {
//统一用 proxy 动态调用,模拟多态
pro::proxy<DrawableAndResizableFacade> cir = Circle{};
pro::proxy<DrawableAndResizableFacade> img = Image{};
cir.draw();
cir.resize(2.0);
img.draw();
img.resize(0.5);
}查看内存布局
通过源码
如果有源码,可直接通过 clang++ 查看内存布局:
clang++ -Xclang -fdump-record-layouts -stdlib=libc++ -std=c++11 -fsyntax-only AoSoA.cpp输出示意:
*** Dumping AST Record Layout
0 | struct Chunk
0 | float[4] x
16 | float[4] y
32 | float[4] z
48 | unsigned int[4] r
64 | unsigned int[4] g
80 | unsigned int[4] b
96 | unsigned int[4] a
| [sizeof=112, dsize=112, align=4,
| nvsize=112, nvalign=4]通过编译产物
如果没有源码,也可通过 llvm-dwarfdump 查看布局信息:
llvm-dwarfdump test.o输出示意:
0x0000002a: DW_TAG_structure_type
DW_AT_name ("Base")
DW_AT_byte_size (16)
DW_AT_decl_file ("test.cpp")
DW_AT_decl_line (1)
0x00000035: DW_TAG_member
DW_AT_name ("_vptr$Base")
DW_AT_type (0x00000040 "void *")
DW_AT_data_member_location (0)
0x00000045: DW_TAG_member
DW_AT_name ("x")
DW_AT_type (0x00000050 "int")
DW_AT_data_member_location (8)
0x00000055: DW_TAG_structure_type
DW_AT_name ("Derived")
DW_AT_byte_size (16)
DW_AT_decl_line (2)
0x00000060: DW_TAG_inheritance
DW_AT_type (0x0000002a "Base")
DW_AT_data_member_location (0)从中可以看到 vptr 和偏移信息等。
内存布局兼容
POD(Plain Old Data)
C98/03 笼统地描述为与 C 语言兼容的简单数据类型,不区分平凡类型和标准布局类型(更严格,相当于取交集);
可通过
std::is_pod_v<T>()判断;
标准布局类型
保证内存布局与 C 兼容,可用于与 C 代码交互(如
extern "C"、结构体映射到硬件寄存器等)。
对构造/析构/拷贝/移动操作无限制;
不能有虚函数或虚基类;
所有非静态成员和基类都是 standard-layout;
所有非静态成员具有相同的访问控制(例如全
public);继承相关限制:
继承树中最多一个类有非静态成员:防止数据成员分散在多个层级类;
第一个非静态成员不能是基类类型:避免跟基类内存布局重叠;
可通过
std::is_standard_layout_v<T>()检测;
std::has_unique_object_representations()(C++17)
每个字段在内存中拥有唯一表示:即严格限制内存布局不能有填充位;
常用于序列化/反序列化;
std::is_layout_compatible() (C++20)
两个类型布局兼容(但不代表
sizeof()一样,可能有填充位);相互之间可通过
std::memcpy()拷贝;
字节序
大小端
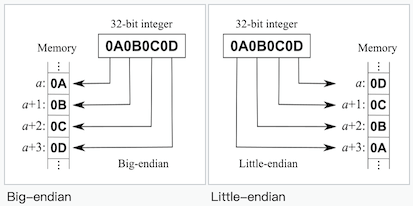
网络字节序
网络协议一般使用大端字节序(重要的头部数据放最前面)。
主机字节序
而主机端 CPU 处理内存数据,绝大多数都使用小端字节序:
电路更简单(地址线复用):CPU 地址总线不需要根据数据类型进行复杂的“偏移计算”,读取低 8 位就是地址
A,读取低 16 位就是地址A和A+1;算术逻辑更自然(从低位开始计算):低位在前,就像在纸上列竖式,低位对齐,进位向高地址(左边)传播,非常符合算术逻辑单元(ALU)从低位向高位逐级计算进位的方式;
类型转换更高效(指针无需偏移):对于大端,如果要取最低位,必须知道这是
int32_t(4 字节),然后访问A+3,在汇编层面增加了额外的指令开销。
处理字节序
原则:发送前转为网络字节序,接收后转为主机字节序。
C 处理字节序
C 语言提供了 htonl(), htons(), ntohl(), ntohs() 四个函数转换字节序:
前缀
h表示主机字节序,n表示网络字节序;后缀
l表示 32 位无符号整数,s表示 16 位无符号整数;
这些函数源于 POSIX 标准(Unix/Linux 通过
<arpa/inet.h>提供,Windows 通过<winsock2.h>提供)。
C++ 处理字节序
C++20 引入了 <bit> 头文件,提供了更通用、类型安全的字节序工具:
#include <bit>
// 判断当前平台字节序
if (std::endian::native == std::endian::big) {
// 无需转换
} else {
// 需要手动交换字节
}
// C++23 新增 `std::byteswap()`
uint32_t net_id = std::byteswap(host_id); // 转换字节序