现代 C++ 跨平台开发-内存篇:类型转换、重载决议、内存模型
从前些年零星参与 Android/iOS C/C++ 跨平台项目,到 24 年真正从零搭建完整的跨所有主流平台的 C++ 项目,再到去年底进入某老牌软件大厂见识横跨近 30 年的庞大 C++ 项目,对 C++ 跨平台开发有了越来越深刻的认识。
虽然之前也有写一些相关的文章,但大多属于管窥蠡测;这里尝试做一个体系化、结构化的梳理。
涉及的知识点颇多,但每个又都不可或缺,否则就无法全面地认识 C++ 这门既古老而又年轻的系统编程语言,以及诸多内存问题的来龙去脉。
借用我对 C++ 之父的一句经典言论的演绎开篇:
C makes it easy to shoot yourself in the foot.
C++ makes it harder, but when you do it blows your whole leg off.
Rust takes away your gun, and gives you a bible.
内容过于庞杂,拆分为一个系列,本文是第 1 篇。
- 现代 C++ 跨平台开发-内存篇:类型转换、重载决议、内存模型
- 现代 C++ 跨平台开发-内存篇:内存管理、智能指针
- 现代 C++ 跨平台开发-内存篇:字节序、内存对齐、内存布局、虚函数表与多态
- 现代 C++ 跨平台开发-内存篇:拷贝、移动、可重定位
- 现代 C++ 跨平台开发-内存篇:函数调用、异常处理、异步等场景的内存管理
- 现代 C++ 跨平台开发-内存篇:STL 内存管理
- 现代 C++ 跨平台开发-内存篇:内存一致性、未定义行为、可观测性
- 现代 C++ 跨平台开发-内存篇:多平台跨层调用场景的内存管理
- 现代 C++ 跨平台开发-内存篇:内存问题分析工具
类型系统
类型是内存的“契约”:
内存只是字节,类型赋予其意义(没有类型的void*,就不知道如何解释它)。
指针:内存地址的抽象
指针
指针 = 地址 + 偏移(类型信息)
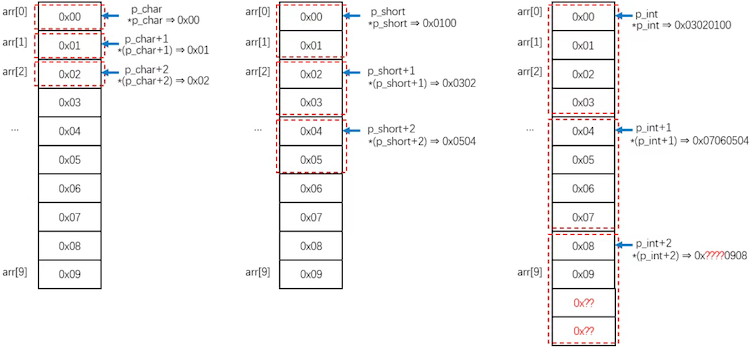
char*,short*,int*虽指向同一地址,但解引用或++/--时需考虑类型信息确定偏移量;
数据指针与函数指针
可能很多 C 语言教材描述,函数指针指向函数入口地址。虽然都是“地址”,但它跟普通数据指针有显著差异。
数据指针:位于数据段,指向的位置存的是数据,可读写;
函数指针:
位于代码段,指向的位置存的是指令,只读、可执行;
成员函数指针,相比普通函数/静态成员函数多了
this指针参数和额外信息(指针偏移、虚函数标记等);
指针与数组
另一个容易被教材误导的例子:将数组名等效为首元素地址。
类型不同:数组包含长度信息;
行为不同:
sizeof()、alignof()都是针对整个数组,而不是首元素;数组名不可修改,指针可以;
数组作为参数,会自动退化为指向首元素的指针。
引用
- 内部实现也是指针,只是做了编译期限制(必须初始化、不允许重新赋值);
nullptr
C 语言
NULL定义为((void*)0),C++ 中就是魔法数0;函数重载和类型推导时会出问题,无法区分指针和数字。
实现:
const class nullptr_t {
public:
template<class T>inline operator T*() const { return 0; } //实现解引用
private:
void operator&() const; //禁止取地址
}指针别名限制
两个指针不会内存重叠(指向同一内存),否则就是 UB;便于编译器做向量化(SIMD)和指令预取等优化;
C
提供了
restrict关键字,限制同类型指针;嵌套调用等场景会有问题;
C++
默认并不支持
restrict关键字,但各大编译器提供了类似扩展;不仅限于同类型指针,非相关类型指针也不行(
int*/char*/std::byte*除外,但int*/float*不行);
Rust 的借用检查机制天然为编译器提供了“无别名”(no-aliasing)的强保证,从而能安全、激进地进行向量化(SIMD)等高级优化。
不少 C 项目被 Rust 重写后号称性能提升,很大程度正是基于此。
安全地取地址
C++ 支持重载 operator&,而 std::addressof() 则可以绕过重载逻辑、安全地获取对象地址:
通常会内联优化,零开销;
支持数组和函数;
不能用于临时对象(没有稳定地址);
template <typename T>
void reset_in_place(T& obj) {
std::destroy_at(std::addressof(obj));
std::construct_at(std::addressof(obj));
}地址相关数值类型
uintptr_t
表示指向 void* 的地址,绝大多数情况下优先使用它(例如跨平台场景用作句柄);
intptr_t
如果涉及到地址的算术运算,可能产生负数,则需要使用它;
ptrdiff_t
当两个指针地址明确位于同一数组或对象,计算地址差值优先考虑用它;
std::array<int, 5> a= {1, 3, 5, 7, 9};
auto *p = a.data();
auto *p3 = &a[3];
std::ptrdiff_t diff = p3 - p;
std::cout << "Distance: " << diff << std::endl;类型转换 - 改变对内存的解释方式
static_cast()
常用于有关系的类型之间转换,编译器会校验,绝大多数情况适用;
用于基本类型间的转换,不能用于基本类型指针间的转换 ;
有继承关系类对象间的转换和类指针间的转换(如 CRTP);
用于左右值引用转换;
T*<->void*(有类型检查,比reinterpret_cast()更安全);
dynamic_cast()
有继承关系的类指针间的转换;
运行时多态,有开销;如果确认类型,直接
static_cast();具有类型检查的功能,转换失败抛出
std::bad_cast异常;
reinterpret_cast()
指针间的类型转换,不如
static_cast()安全,尽量避免;整数和指针间的类型转换;
可以加上
const和volatile,但不能去掉。不能用于将
nullptr转换为其他类型,只能用static_cast()转;
const_cast()
仅用于指针或引用;
仅用于去掉
const;(加上不需要 cast);如果需要多次 cast,一般先用其他 cast,最后
const_cast();运行时转换,不安全(可能崩溃,或属于未定义行为);
void* <-> 函数指针
C++ 严格限制
void*和函数指针的转换,直接转换会警告(reinterpret_cast也不行);如果确实要转换,可通过
uintptr_t中转(绕过编译器检查),但仅限于普通函数和静态成员函数。
普通成员函数包含额外信息,一般远大于
void*的 8 字节;
C++23 的 Deducing this 只是语法糖,并没有抹平它跟普通函数在内存布局和 ABI 方面的鸿沟。
void fv() {
std::cout << "Hello World!" << std::endl;
}
using VoidFuncT = void(*)();
int main() {
// 函数指针 -> void*
// void* ptr = (void*)fv;
void* ptr = reinterpret_cast<void*>(reinterpret_cast<uintptr_t>(fv));
// void* -> 函数指针
// auto func = (VoidFuncT)ptr;
auto func = reinterpret_cast<VoidFuncT>(reinterpret_cast<uintptr_t>(ptr));
func();
return 0;
}模板元编程场景的类型标识处理
编译时行为,安全高效。
const 标识
仅处理顶层
const标识。
std::is_const<T>();std::add_const<T>();std::remove_const<T>();
volatile 标识
std::is_volatile<T>();std::add_volatile<T>();std::remove_volatile<T>();
引用标识
std::is_reference_v<T>();std::is_lvalue_reference<T>();std::is_rvalue_reference<T>();std::add_lvalue_reference<T>();std::add_rvalue_reference<T>();std::remove_reference<T>();
std::decay_t()
完全模拟函数按值传参过程的类型退化。
移除(顶层)
const、volatile、引用标识;数组类型退化为指针类型;
函数签名退化为函数指针类型;
std::remove_cvref(C++20)
安全地获取裸类型。
- 仅移除(顶层)
const、volatile、引用标识,不搞类型退化。
重载决议 - 隐式类型转换优先级
精确匹配
类型完全相同;
加上
const/volatile;数组 -> 指针;
std::function-> 指针;
类型提升
bool/char/short->int;float->double;
标准转换
int->long/float;double->float;Derived*->Base*;指针/数字 ->
bool;
用户定义的转换
重载构造函数,如
string的const char*构造函数;重载运算符:
class Zero {
public:
operator int() const {
return 0;
};
operator float() const {
return 0.0f;
};
};
void print(int i) {
std::cout "int:" << i;
}
void print(float f) {
std::cout "float:" << f;
}
//print(Zero{}); //存在两个相同优先级的用户自定义转换,存在二义性,编译报错
print(static_cast<int>(Zero{}));RTTI - 运行时类型元数据
编译器遇到
typeid(T)或dynamic_cast()时,自动为类型T生成一个type_info对象,保存在只读数据段(.rodata/.rdata)中的全局静态对象;
可通过-fno-rtti禁用,则所有使用了typeid(T)或dynamic_cast()的代码都会编译失败;
class type_info {
public:
virtual ~type_info();
bool operator==(const type_info& rhs) const;
bool operator!=(const type_info& rhs) const;
const char* name() const;
private:
const char* __name; //类型的 mangled name(如"i"表示 int)
}RTTI is useful only in certain narrow cases… In most cases, the need for RTTI indicates a design flaw.
Google C++ Style Guide 指出,RTTI 某些情况下很管用(单元测试/序列化),但绝大多数时候都应该避免 – 不仅因为其性能开销,更因为其违反软件设计原则:
中心化,违反开闭原则;
抽象依赖具体,破坏分层;
新增类型可能引发意想不到的问题,代码很难维护;
if (typeid(*data) == typeid(D1)) {
//...
} else if (typeid(*data) == typeid(D2)) {
//...
} else if (typeid(*data) == typeid(D3)) {
//...
}那么如何规避呢?
typeid():可将中心化逻辑抽象为虚函数接口,子类负责实现,或直接改为函数重载;dynamic_cast():绝大多数时候如果确认真实类型,直接使用static_cast()。
静态类型信息
类型判断
template
struct is_floating_point_type {
static const bool value = false;
};
template <>
struct is_floating_point_type {
static const bool value = true;
};
template <>
struct is_floating_point_type {
static const bool value = true;
};类型比较
template
struct is_same {
static constexpr bool value = false;
};
// 偏特化:当 T 和 U 相同时
template
struct is_same<T, T> {
static constexpr bool value = true;
};类型标识
template <typename T>
void* get_type_id() {
static char token; //针对每个类型特化,生成唯一的静态类型标识
return &token;
}
template <typename T>
T* any_cast(any* a) {
// 直接比对类型标识,不依赖 RTTI 的 type_info
if (a && a->type_id_ == get_type_id<T>()) {
return static_cast<T*>(a->ptr_);
}
return nullptr;
}内存模型
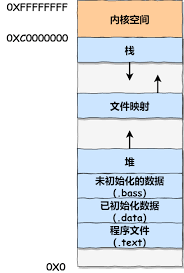
栈
栈是向下生长的(高地址在上);
函数内局部变量;
效率高:存在寄存器,且有 push/pop 指令;
容量小:每个线程都有固定大小的栈空间;
函数调用前后,由系统自动分配和释放;
堆(自由存储区)
堆是向上生长的(低地址在上);
需手动释放;
几乎无空间限制;
容易产生碎片;
全局/静态区
static
作用于全局变量/函数:
改变链接属性:只能在模块内使用,外部无法通过
extern访问;既能实现封装性,也能避免符号冲突;
C 语言中,静态变量在代码执行前就会初始化,不能用变量赋值;
C++ 更推荐使用匿名
namespace实现隐藏内部符号;
作用于函数内局部变量:
- 改变存储属性:保存在静态区的(
.data或.bss段),不会随着函数执行完销毁;
- 改变存储属性:保存在静态区的(
作用于 C++ 类:
静态成员变量:存在静态区;
静态成员函数:
跟普通成员函数一样位于
.text代码段;没有隐式
this指针参数,通过类名直接访问,仅能访问静态成员;不同于全局静态函数的模块内部链接属性,静态成员函数具有外部链接属性;
常量区
const相关成员一般存储在只读段(.rodata);若某些情况被优化为编译期常量,则不占运行时存储。
const
强调运行期不可修改;
const变量:局部:
可能被优化为编译期常量,否则放栈上;
const_cast()可能侥幸成功,但属于未定义行为;
全局:
放在只读段;
const_cast()会导致运行时崩溃,因为只读段读写权限不可逾越;
字符串字面量:
相同字符串只存一份;
永远在只读段;
从右向左读( * 读成 pointer to );
const在类型前后是等价的;
char * const cp; //cp is a const pointer to char;
const char * p; //p is a pointer to const char;
char const * p; //同上;constexprconsexpr
强调编译期可求值,便于编译器深入优化;
修饰变量:
不仅跟
const一样表示是不可变的,而且是编译期可确定的;不占用运行时存储。
修饰函数:
若参数编译期可确定,则会在编译期计算出函数返回值;
否则,等同于普通函数;
consteval(C++20)
用于修饰函数,比
constexpr更严格,强制编译期可求值,否则编译错误;consteval函数返回值也只能用于constexpr变量,而不能用于普通运行期变量赋值;如果要同时兼容编译期与运行期计算(支持退化),只能改为
constexpr函数。
consteval unsigned long long hash(std::string_view sv) {
unsigned long long h = 5381;
for (char c : sv) h = h * 31 + static_cast<unsigned char>(c);
return h;
}
int main() {
//auto h0 = hash("hello"); //编译错误
constexpr auto h1 = hash("world");
auto h2 = h1;
std::cout << h2 << std::endl;
}编译器默认初始化行为
全局/静态成员,执行零初始化(Zero-initialization):
数值类型置零,指针置空;
调用默认构造函数;
普通局部成员:
数值和指针类型,不做任何处理,也就是垃圾值!
自定义类型,调用默认构造函数(如果构造函数并未初始化成员,则其非静态成员仍是垃圾值);
读取未初始化的垃圾值属于未定义行为,虽不一定会崩溃,但表现不符合预期,可能不同平台/不同编译类型的行为都不一样。
静态局部成员:
在首次调用时初始化;
C++11 开始,编译器保证线程安全,可用于实现单例;
为何编译器不保证始终初始化
C++ 的哲学是“零成本抽象”,尤其是默认行为更应该零成本:
for (auto i = 0; i < 1000000; ++i) {
int temp; // 如果自动初始化为 0,就要执行 100 万次写内存
// ... 实际马上会被赋值
temp = compute(i);
}最佳实践
int a; // 我知道风险,不要初始化(高性能场景)
int b = 0; // 我要确定值
int c{}; // C++11 引入的值初始化,安全且明确
std::vector<int> v{}; // 空 vector
MyStruct s{}; // 所有成员零初始化