还在用 OpenGL? Metal 和 Vulkan 了解一下!

最近做一个移动端动效的项目需要用到 OpenGL。
我们知道它基于 C 语言实现,拥有跨平台支持;但诞生于上世纪 90 年代的它,必然有历史局限性:
- 不支持预编译 Shader;
- 不支持多 CPU 线程;
- 不支持直接访问底层 GPU CommandBuffer;
所以,苹果 WWDC 2014 推出了新的图形渲染技术 Metal,并且从 iOS 12 开始将 OpenGL 相关 API 标记为 deprecated。
同样在 2014 年微软也发布了 DirectX 12,而开发 OpenGL 的 Khronos 则推出了 Vulkan。
OpenGL 为何存在种种问题
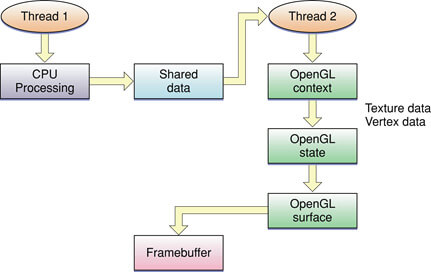
上图所示为 OpenGL 的线程模型:
- 一个 CPU 线程负责数据处理;
- 一个 GL 线程负责创建 GL context,维护 GL 状态、顶点、纹理等数据,操作 FrameBuffer;
那么,OpenGL 为什么不支持多 CPU 线程呢?
It was designed before multiple CPU cores were even available to the general consumer, and long before just about every part of a graphics pipeline was programmable.
…
The central concept of OpenGL is a state machine.
…
Being state based, and because any of the API calls has the potential to change state, this makes multi-threaded access to an OpenGL context very difficult.
…
Furthermore about a state based design, is that OpenGL implementations must ensure that the state is always valid.
It must ensure that data is correctly bound, in range, and that nothing will break the system.
总结下:
- 在它设计之初,多核 CPU 还未在消费领域普及;
- 它是基于状态机设计的,而任何 API 调用都可能改变状态,引入多线程必然会带来数据同步难题;
- 它需要频繁检测状态合法性,也严重影响了性能;
Metal 的优势
更高级的 Shader 语言
与 OpenGL Shader 类似 C 语言的语法不同,Metal Shader 基于 C++ 11,语法更灵活,而且将 Vertex 和 Fragment 整合到了一起:
#include <metal_stdlib>
using namespace metal;
// Define the data type that corresponds to the layout of the vertex data.
struct VertexIn {
packed_float4 position;
packed_float2 texCoords;
};
// Define the data type that will be passed from vertex shader to fragment shader.
struct VertexOut {
float4 position [[position]];
float2 texCoords [[user(tex_coords)]];
};
// Uniforms
struct Uniforms {
float4x4 modelMatrix;
};
// Vertex shader function
vertex VertexOut vertex_func(constant VertexIn* vertices [[buffer(0)]],
constant Uniforms& uniforms [[buffer(1)]],
ushort index [[vertex_id]]) {
VertexIn in = vertices[index];
VertexOut out;
out.position = uniforms.modelMatrix * float4(in.position);
out.texCoords = in.texCoords;
return out;
}
// Fragment shader function
fragment float4 fragment_func(VertexOut in [[stage_in]],
texture2d<float/*, access::sample*/> texture [[texture(0)]],
sampler texSampler [[sampler(0)]]) {
return texture.sample(texSampler, in.texCoords);
}支持 Shader 预编译
与 OpenGL Shader 在应用运行时才编译链接不同,Metal Shader 代码会和应用代码一起被编译为 .metallib:
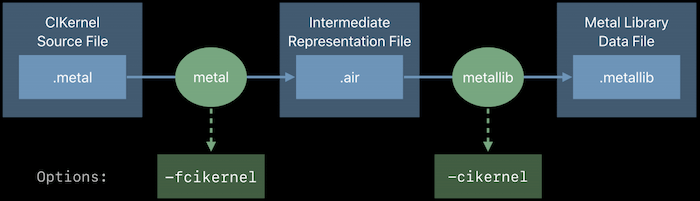
运行时直接加载:
id<MTLLibrary> library = [device newDefaultLibrary];
id<MTLFunction> vertexProgram = [library newFunctionWithName:vertexFuncName];
id<MTLFunction> fragmentProgram = [library newFunctionWithName:fragmentFuncName];而且与 OpenGL 在每帧都需要做状态校验不同,Metal 将状态校验前置到了加载 Shader 的时候,这样在每一帧的时候就能专注于 GPU 操作。

支持多线程异步操作 CommandBuffer
Metal 摒弃了状态机的概念,所以没有状态同步的问题;
因为状态校验前置到了加载时,而且驱动层的开销变得很小,所以帧渲染时可以在多个线程分别提交指令到 CommandBuffer。
实际上指令最终仍然是被单线程序列化丢到 CommandQueue 提交到 GPU 的,但是这个开销很小。
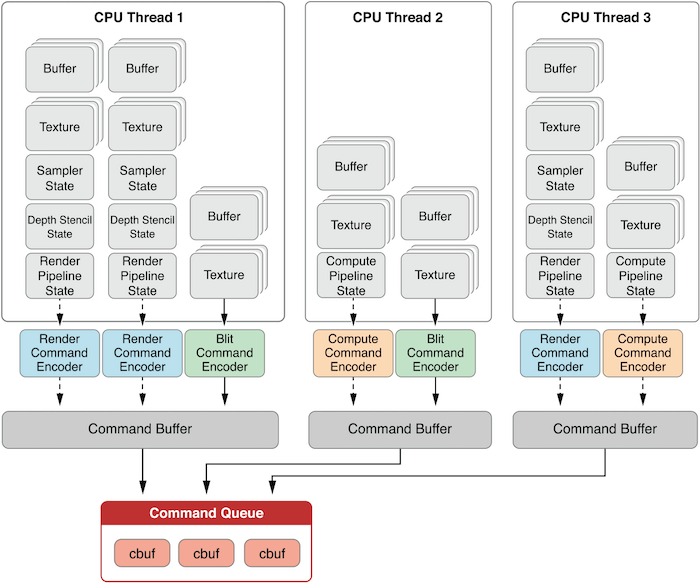
相关概念:
- RenderPipelineDescriptor: 配置渲染管线(shader、buffer、光栅化/采样、附件的 blend 策略等);
- RenderPassDescriptor: 配置附件的目标纹理、ClearColor 等;
- RenderCommandEncoder: 将 draw-call 转换成 GPU 指令;
- CommandBuffer: 待提交的指令缓冲区;
- CommandQueue: 指令最终提交到的队列;
OpenGL 中的 FrameBuffer 并不是真正的 Buffer,而是管理 Texture 和 RenderBuffer 这两种附件,其中 RBO 常用于模板和深度测试;
而 Metal 中没有 FBO 和 RBO 的概念,通过 RenderPipelineDescriptor 和 RenderPassDescriptor 可直接操作颜色/深度/模板附件。
下面是代码示例:
-(void)renderDrawable:(id<CAMetalDrawable>)drawable {
// CommandBuffer is a set of commands that will be executed and encoded in a compact way that the GPU understands.
id<MTLCommandBuffer> commandBuffer = [_commandQueue commandBuffer];
// RenderPassDescriptor describes the actions Metal should take before and after rendering.(Like glClear & glClearColor)
MTLRenderPassDescriptor* renderPassDescriptor = [MTLRenderPassDescriptor renderPassDescriptor];
renderPassDescriptor.colorAttachments[0].texture = drawable.texture;
renderPassDescriptor.colorAttachments[0].loadAction = MTLLoadActionClear;
renderPassDescriptor.colorAttachments[0].storeAction = MTLStoreActionStore;
renderPassDescriptor.colorAttachments[0].clearColor = MTLClearColorMake(0, 0, 0, 0);
// RenderCommandEncoder is used to convert from draw calls into the language of the GPU.
id<MTLRenderCommandEncoder> renderEncoder = [commandBuffer renderCommandEncoderWithDescriptor:renderPassDescriptor];
[renderEncoder setCullMode:MTLCullModeFront];
[renderEncoder setRenderPipelineState:_renderPipelineState];
[renderEncoder setVertexBuffer:_vertexBuffer offset:0 atIndex:0];
[renderEncoder setVertexBuffer:_uniformBuffer offset:0 atIndex:1];
[renderEncoder setFragmentTexture:_texture atIndex:0];
[renderEncoder setFragmentSamplerState:_samplerState atIndex:0];
[renderEncoder drawIndexedPrimitives:MTLPrimitiveTypeTriangleStrip indexCount:_indexBuffer.length/sizeof(uint16_t) indexType:MTLIndexTypeUInt16 indexBuffer:_indexBuffer indexBufferOffset:0];
[renderEncoder endEncoding];
[commandBuffer addCompletedHandler:^(id<MTLCommandBuffer> buffer) {
}];
[commandBuffer presentDrawable:drawable];
//[commandBuffer waitUntilCompleted];
[commandBuffer commit];
}可以看到 CommandBuffer 里面的 command 执行是异步的,可以设置完成回调;
当然我们也可以通过 waitUntilCompleted 同步提交,不过通常不推荐这样。
Vulkan: 俺也一样!
基本特性
Vulkan 基于 AMD 的 Mantle 项目(因为没有太多厂商采用死掉了),吸取了其中的精华。
Vulkan 拥有和 Metal 类似的优势:
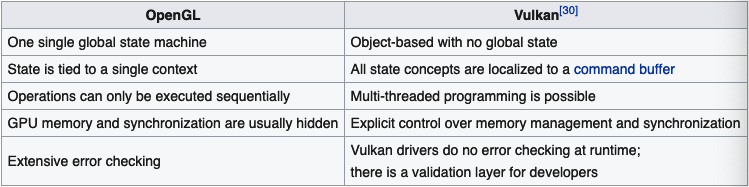
OpenGL 的很多工作都在驱动层(错误检测、内部资源分配和释放等),而 Vulkan 将这部分工作移到了上层:

这样虽增加了应用层的复杂度(比 Metal 还复杂),也带来了不少好处:
增加了应用层对底层硬件的控制力,有助于性能优化;(类似于 C/C++ 虽然没 GC 用起来麻烦,但性能可做到极致)
驱动层很薄,易维护;
更多相关内容可参考 Transitioning from OpenGL to Vulkan。
核心概念
VkDevice
VkPhysicalDevice:不同于 Metal,Vulkan 有单独的物理设备的概念,用于查询特性的支持情况;VkDevice可类比为 Metal 的MTLDevice,是物理设备的抽象(逻辑设备),后续各种 API 操作的 handle;
Vulkan 通常的初始化流程为:
vkCreateInstance() → vkEnumeratePhysicalDevices() → vkCreateDevice()。
VkShaderModule
VKShaderModule 用于对 Shader 的操控,大致可类比 Metal 的 MTLLibrary。
VkPipeline
VkPipeline 可类比为 Metal 的 MTLRenderPipelineDescriptor,用于配置渲染管线;但似乎比后者更强大:
VkPipelineShaderStageCreateInfo配置 shader 信息;VkPipelineVertexInputStateCreateInfo配置顶点数据;VkPipelineInputAssemblyStateCreateInfo配置绘制类型(三角形/点/线);VkPipelineRasterizationStateCreateInfo配置光栅化;VkPipelineMultisampleStateCreateInfo配置 MSAA(多重采样抗锯齿);VkPipelineColorBlendAttachmentState配置颜色混合方式;
VkRenderPass
VkRenderPass 可类比为 Metal 的 MTLRenderPassDescriptor;
VkCommandBuffer & VkQueue
Vulkan 同样有 CommandBuffer 和 Queue 的概念。
VkCommandBuffer可类比 Metal 的MTLCommandBuffer;VkCommandPool是 Vulkan 独有的,用于创建VkCommandBuffer;VkQueue可类比 Metal 的MTLCommandQueue;
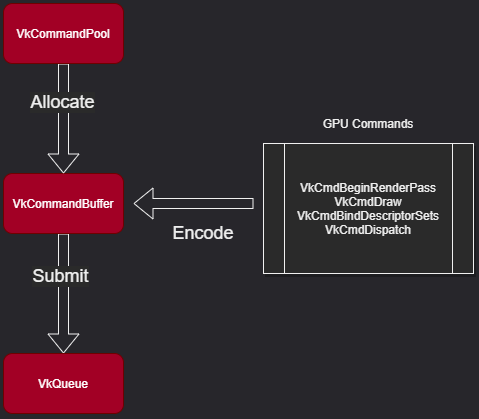
VkSurfaceKHR & VkSwapchainKHR
我们知道,OpenGL 渲染到屏幕需要窗口系统 EGL,Vulkan 也不例外:
渲染结果输出到
VkFrameBuffer;VkSurfaceKHR类似EGLSurface,代表窗口;VkSwapchainKHR基本作用类似eglSwapBuffers(),用于交换 buffer,触发上屏;但相比 EGL 仅有的这个方法,它更加专业而强大,可配置minImageCount等很多参数;
VkImage & VkImageView
Vulkan 中,不管是 SwapChain 的输出,还是上传纹理,都需要通过 VkImage;
而访问它则要通过 VkImageView,它定义了访问 VkImage 的区域、方式等;
Metal 中只有一个 MTLTexture。
VkBuffer & VkBufferView
VkBuffer 就是数据缓冲区,Shader 如果要访问它必须通过 VkBufferView;
Metal 只有一个 MTLBuffer。
VkFence & VkSemaphore
熟悉 OpenGL 的都知道 glFenceSync(),基于信号量实现 CPU/GPU 同步。
Vulkan 也提供了类似的同步机制:
VkFence用于同步 CPU/GPU,对标glFenceSync();VkSemaphore用于同步VkQueue(可以有多个);VkEvent和vkCmdPipelineBarrier用于同步VkCommandBuffer;
这里再对比下 Metal 的同步机制:
虽然命名和职责没有完全对应,但各方面能力都是对齐的。
SPIR-V
Shader 这块,Vulkan 采用 SPIR-V(Standard Portable Intermediate Representation for Vulkan) 这一二进制中间表示。
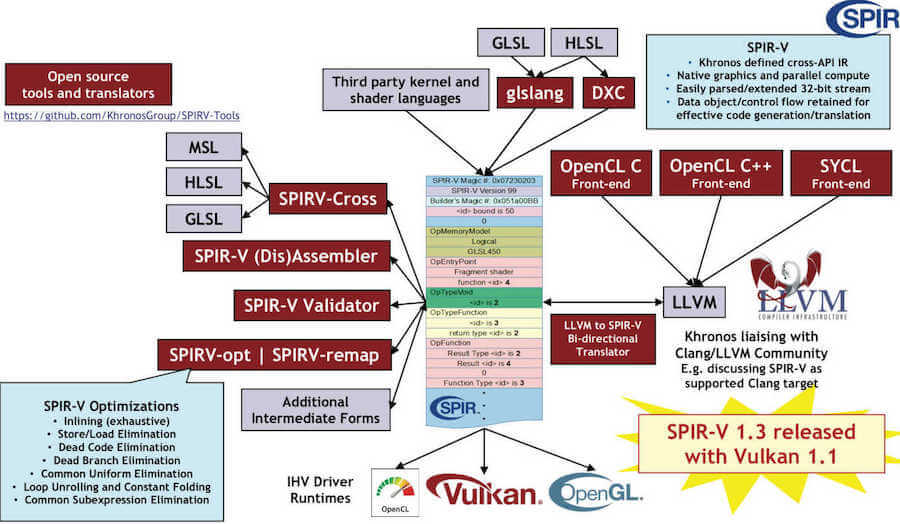
SPIR-V 因为基于 LLVM 编译器后端,所以能支持多种 Shader 语言(GLSL/HLSL等)。
它通过特定的编译器(比如 glslang)将 Shader 编译为厂商无关的中间层二进制表示:
glslangValidator -G -V -S vertex.glsl -o spirv/vertex.spv而二进制表示转换为最终硬件厂商代码的过程则由驱动完成。
由于错误校验在转换为 spv 的过程中就完成了,所以运行时无需编译链接,直接加载即可:
glShaderBinary(1, shader, GL_SHADER_BINARY_FORMAT_SPIR_V_ARB, buffer, file_size);当然,为了让我们原来的 Shader 兼容 SPIR-V,我们需要做一些改动,通过 layout 指定输入/输出属性/变量的位置和绑定点:
#version 450
layout(std140, binding = 0) uniform matrix_state {
mat4 vmat;
mat4 projmat;
mat4 mvmat;
mat4 mvpmat;
vec3 light_pos;
} matrix
layout(location = 0) in vec4 attr_vertex;
layout(location = 1) in vec3 attr_normal;
layout(location = 2) in vec2 attr_texcoord;
layout(location = 3) out vec3 vpos;
layout(location = 4) out vec3 norm;
layout(location = 5) out vec3 ldir;
layout(location = 6) out vec2 texcoord;
void main() {
gl_Position = matrix.mvpmat * attr_vertex;
vpos = (matrix.mvmat * attr_vertex).xyz;
norm = mat3(matrix.mvmat) * attr_normal;
texcoord = attr_texcoord * vec2(2.0, 1.0);
ldir = matrix.light_pos - vpos;
}Android 8.0 才提供了对 Vulkan 的完整支持,NDK 内置的 shaderc 可用于 SPIR-V 编译:
// compile into spir-V shader
shaderc_compiler_t compiler = shaderc_compiler_initialize();
shaderc_compilation_result_t spvShader = shaderc_compile_into_spv(
compiler, glslShader.data(), glslShaderLen, getShadercShaderType(type),
"shaderc_error", "main", nullptr);
if (shaderc_result_get_compilation_status(spvShader) != shaderc_compilation_status_success) {
return static_cast<VkResult>(-1);
}
// build vulkan shader module
VkShaderModuleCreateInfo shaderModuleCreateInfo {
.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO,
.pNext = nullptr,
.flags = 0,
.codeSize = shaderc_result_get_length(spvShader),
.pCode = (const uint32_t*)shaderc_result_get_bytes(spvShader),
};
VkResult result = vkCreateShaderModule(vkDevice, &shaderModuleCreateInfo, nullptr, shaderOut);
shaderc_result_release(spvShader);
shaderc_compiler_release(compiler);考虑到版本分布和成本,我们暂时只在 iOS 平台做了 Metal 适配。
更多关于 Vulkan 和 SPIR-V 内容可参考:
Metal 适配
API 差异
Metal API 和 OpenGL 差异还是比较大的,限于篇幅这里就不一一介绍 API,仅仅列一张我自己整理的对比图(高清可放大):
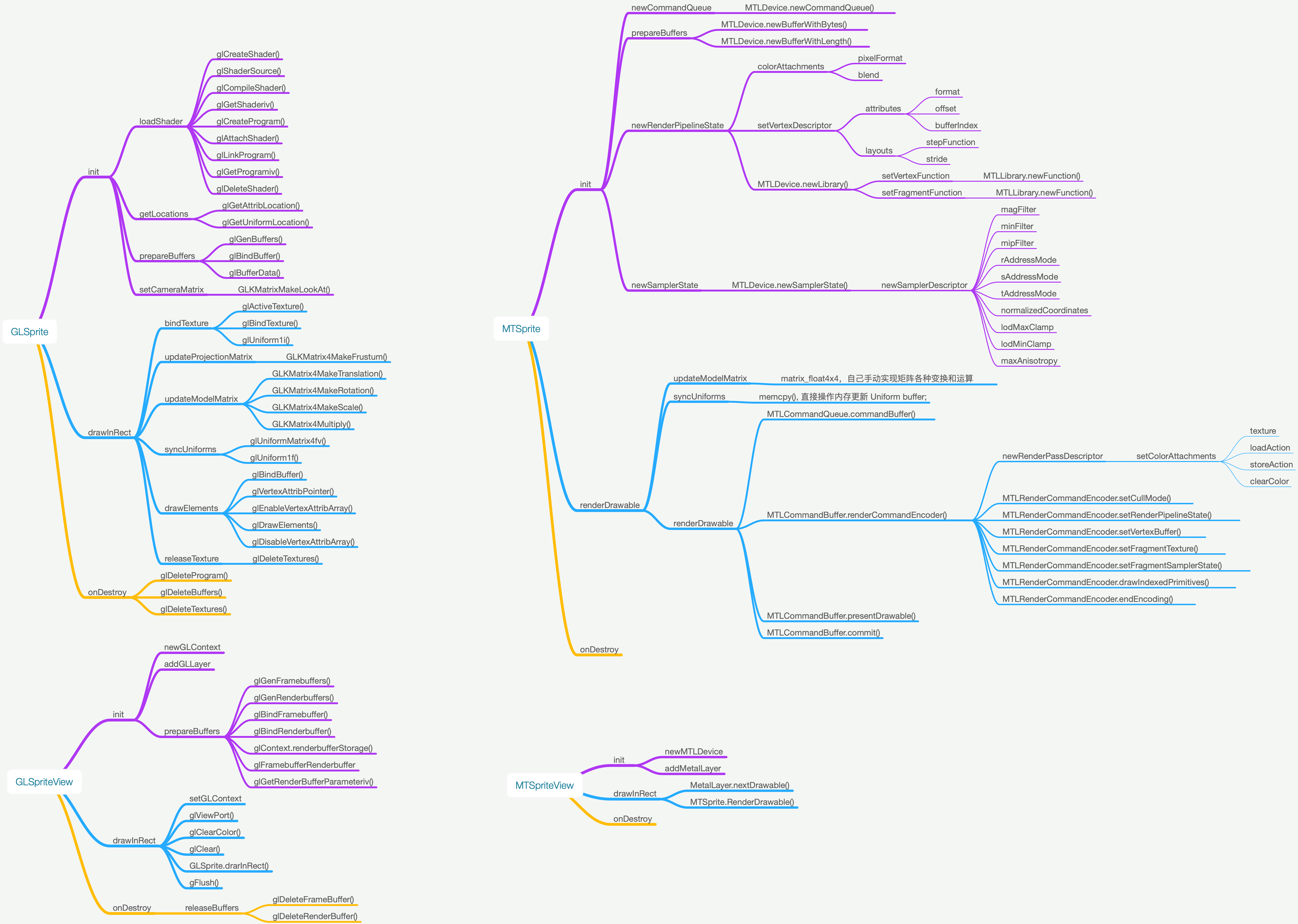
不过几个关键流程还是基本一致的:
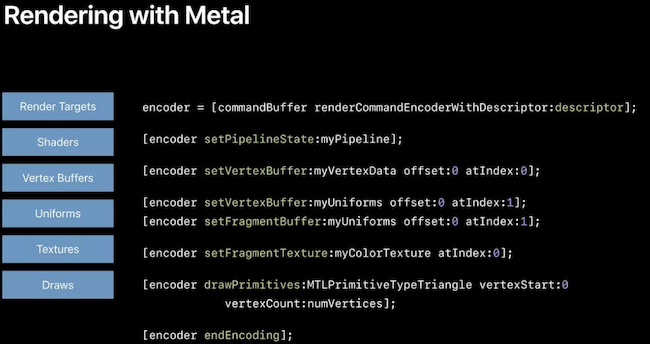
自定义 Metal View
iOS 提供了类似 Android GLSurfaceView 的封装了 OpenGL 运行环境的 View 组件 GLKView,对于 Metal 则是 MTKView。
但是,因为要同时适配 OpenGL 和 Metal,考虑到代码复用,我们选择基于 UIView 自己分别创建 GLView 和 MTView。其实主要就是创建各自的 CALayer:
-(instancetype)initWithFrame:(CGRect)frame {
if (self = [super initWithFrame:frame]) {
// An abstraction of GPU. Used to create buffers, textures, function libraries..
_device = MTLCreateSystemDefaultDevice();
// CAMetalLayer is a subclass of CALayer that knows how to display the contents of a Metal framebuffer.
_metalLayer = [CAMetalLayer layer];
_metalLayer.frame = self.bounds;
_metalLayer.opaque = NO;// Make layer transparent
_metalLayer.device = _device;
_metalLayer.pixelFormat = MTLPixelFormatBGRA8Unorm;
[self.layer addSublayer:_metalLayer];
}
return self;
}
-(void)drawRect:(CGRect)rect {
[super drawRect:rect];
for (MTSprite* sprite in self.sprites) {
// In order to draw into the Metal layer, we first need to get a ‘drawable’ from the layer.
// The drawable object manages a set of textures that are appropriate for rendering into.
[sprite renderDrawable:[_metalLayer nextDrawable] inRect:rect];
}
}需要特别注意的一点就是 CAMetalLayer 的 opaque 属性必须要设置为 NO,否则渲染出来就会黑屏。
Alpha 通道混合
当我们在渲染 2D 纹理的时候,如果素材存在半透明像素,渲染出来可能有锯齿黑边,这里涉及到 Alpha 混合的问题。
在计算机图形学里面,颜色混合是通过下面的公式:
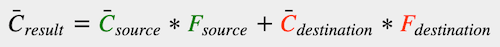
其中:
- Cresult 、Csource、Cdestination 分别表示 最终的颜色、待渲染的纹理颜色、当前 buffer 中的颜色;
- Fsource 和 Fdestination 是对应的两个因子,可以用来设置混合策略。
下面列出了所有的混合策略:
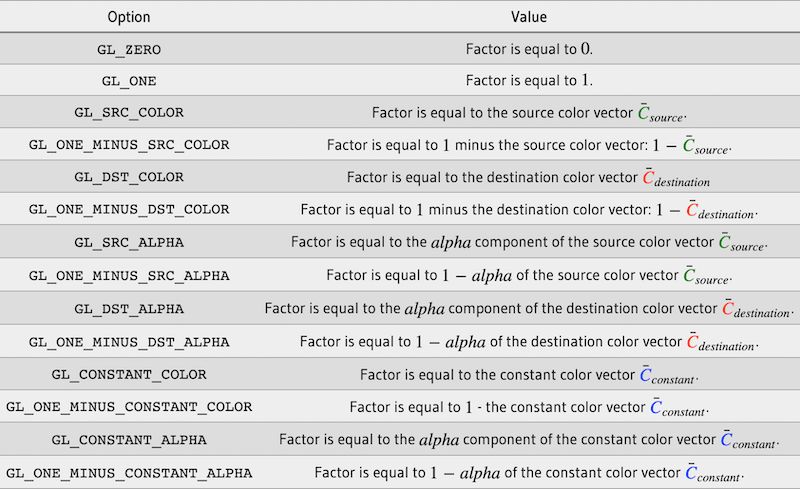
对于 Alpha 通道混合,我们一般将 Fsource 我们设置为 alpha,Fdestination 设置为 1 - alpha。
对应的代码如下:
// Enable blend:
renderPipelineDescriptor.colorAttachments[0].blendingEnabled = YES;
// '+' in the formula above:
renderPipelineDescriptor.colorAttachments[0].rgbBlendOperation = MTLBlendOperationAdd;
renderPipelineDescriptor.colorAttachments[0].alphaBlendOperation = MTLBlendOperationAdd;
// Source color blend factor:
renderPipelineDescriptor.colorAttachments[0].sourceRGBBlendFactor = MTLBlendFactorSourceAlpha;
renderPipelineDescriptor.colorAttachments[0].sourceAlphaBlendFactor = MTLBlendFactorSourceAlpha;
// Destination color blend factor:
renderPipelineDescriptor.colorAttachments[0].destinationRGBBlendFactor = MTLBlendFactorOneMinusSourceAlpha;
renderPipelineDescriptor.colorAttachments[0].destinationAlphaBlendFactor = MTLBlendFactorOneMinusSourceAlpha;资源更新
苹果官方推荐使用三级缓冲来更新资源:
创建三帧的资源缓冲区来形成一个缓冲池,CPU 将每一帧的数据按顺序写入缓冲区供 GPU 使用;
当 GPU 触发回调时,CPU 将释放该帧的缓冲区,并于下一帧使用。
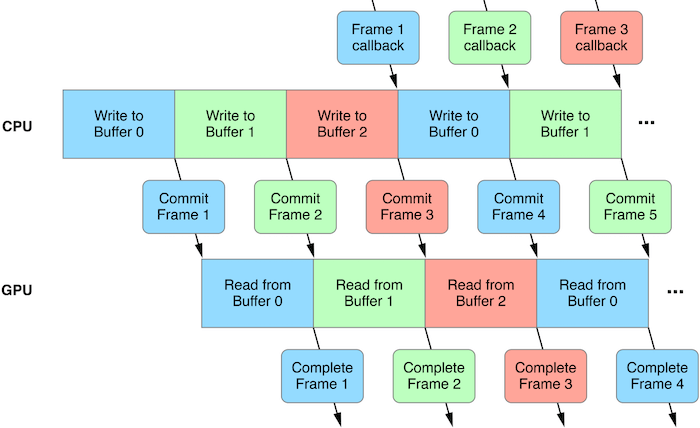
首先定义缓冲区和信号量:
id <MTLBuffer> myUniformBuffers[3];
dispatch_semaphore_t frameBoundarySemaphore = dispatch_semaphore_create(3);
NSUInteger currentUniformIndex = 0;渲染循环中,在 CommandBuffer 的 CompletedHandler 中通过信号量更新:
dispatch_semaphore_wait(frameBoundarySemaphore, DISPATCH_TIME_FOREVER);
currentUniformIndex = (currentUniformIndex + 1) % 3;
[self updateUniformResource: myUniformBuffers[currentUniformIndex]];
[commandBuffer addCompletedHandler:^(id<MTLCommandBuffer> commandBuffer) {
dispatch_semaphore_signal(frameBoundarySemaphore);
}];
[commandBuffer commit];OpenGL 和 Metal 混编
OpenGL 毕竟存在了几十年,苹果也考虑到很多大型项目肯定存在历史遗留 OpenGL 代码需要兼容:通过 CVPixelBuffer 可以创建兼容 OpenGL 和 Metal 的 Texture。
首先打开兼容 OpenGL 和 Metal 的开关:
NSDictionary* cvBufferProperties = @{
(__bridge NSString*)kCVPixelBufferOpenGLCompatibilityKey : @YES,
(__bridge NSString*)kCVPixelBufferMetalCompatibilityKey : @YES,
};创建 CVPixelBuffer 来共享内存:
CVReturn cvret = CVPixelBufferCreate(kCFAllocatorDefault,
size.width, size.height,
_formatInfo->cvPixelFormat,
(__bridge CFDictionaryRef)cvBufferProperties,
&_CVPixelBuffer);创建 OpenGL 纹理:
CVReturn cvret;
// Create an OpenGL ES CoreVideo texture cache from the pixel buffer.
cvret = CVOpenGLESTextureCacheCreate(kCFAllocatorDefault,
nil,
_openGLContext,
nil,
&_CVGLTextureCache);
// Create a CVPixelBuffer-backed OpenGL ES texture image from the texture cache.
cvret = CVOpenGLESTextureCacheCreateTextureFromImage(kCFAllocatorDefault,
_CVGLTextureCache,
_CVPixelBuffer,
nil,
GL_TEXTURE_2D,
_formatInfo->glInternalFormat,
_size.width, _size.height,
_formatInfo->glFormat,
_formatInfo->glType,
0,
&_CVGLTexture);
// Get an OpenGL ES texture name from the CVPixelBuffer-backed OpenGL ES texture image.
_openGLTexture = CVOpenGLESTextureGetName(_CVGLTexture);创建 Metal 纹理:
CVReturn cvret;
// Create a Metal Core Video texture cache from the pixel buffer.
cvret = CVMetalTextureCacheCreate(
kCFAllocatorDefault,
nil,
_metalDevice,
nil,
&_CVMTLTextureCache);
// Create a CoreVideo pixel buffer backed Metal texture image from the texture cache.
cvret = CVMetalTextureCacheCreateTextureFromImage(
kCFAllocatorDefault,
_CVMTLTextureCache,
_CVPixelBuffer, nil,
_formatInfo->mtlFormat,
_size.width, _size.height,
0,
&_CVMTLTexture);
// Get a Metal texture using the CoreVideo Metal texture reference.
_metalTexture = CVMetalTextureGetTexture(_CVMTLTexture);既然,OpenGL 和 Metal 可以混编,那能否直接将旧的 OpenGL 代码直接转换成 Metal 代码?
技术上肯定是可以实现的,glsl-optimizer 这个项目就可以将 GLSL 转换为 Metal Shader,而 Khronos 更是直接推出了 MoltenGL 项目,只不过目前不开源且收费。
MoltenVK: 助力 Vulkan 全平台制霸!
苹果为自家 iOS/MacOS 设备推出的 Metal 显然没法在其他平台应用,那反过来 Vulkan 能否覆盖 Android/iOS 两大平台呢?
曾经推出跨平台 OpenGL 的 Khronos 又在 2016 年推出了 MoltenVK(18 年 2 月免费开源),它提供了一个 iOS/MacOS 运行时库,能将 Vulkan API 映射为 Metal API:
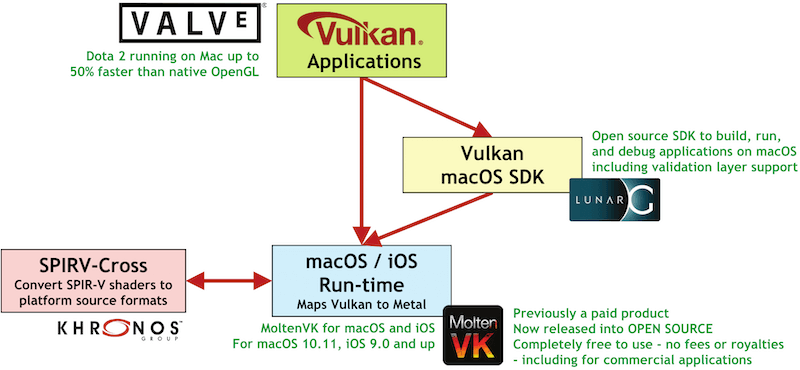
API 做了映射,Shader 脚本也要能打通才行。
MoltenVK 提供了两种方式将 SPIR-V 转换成 Metal Shader:
vkCreateShaderModule()函数可自动做转换;MoltenVKShaderConverter命令行工具可手动转换;
Khronos 开源的 SPIRV-Cross 甚至支持将 SPIR-V 转换为各种 shader(GLSL/Metal/HLSL)。
MoltenVK 没有使用任何私有 API(数据交换应该使用了 CVPixelBuffer 和 IOSurface),所以不用担心苹果审核问题。
目前,Valve 旗下 Dota 2 和 Artifact 两款游戏的 MacOS/iOS 版本已经采用 MoltenVK 实现,Google 推出的跨平台实时渲染引擎 Filament 也采用了 MoltenVK。
下面是 Dota 2 的 Vulkan 版本和 OpenGL 版本 FPS 数据对比:
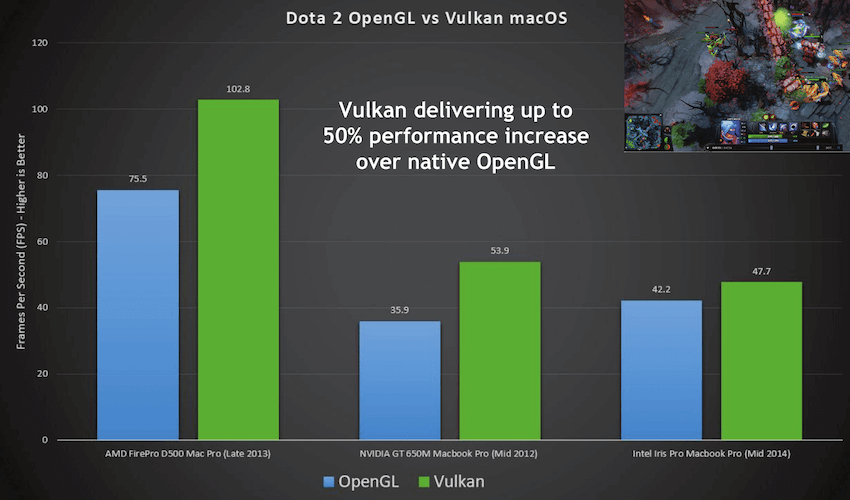
可以预见,打通 iOS/MacOS 的 Vulkan 未来可能全平台制霸。
参考: